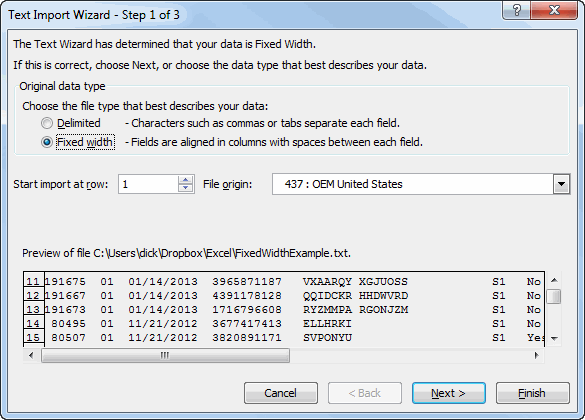
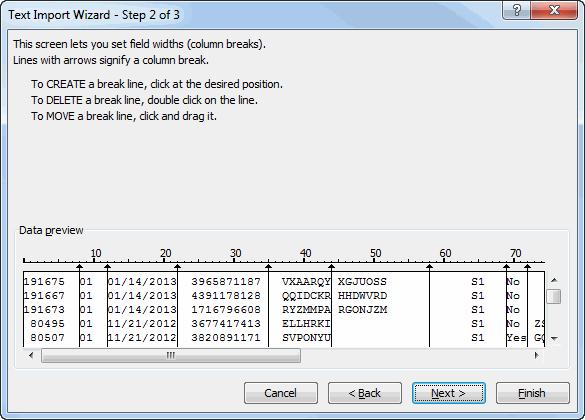
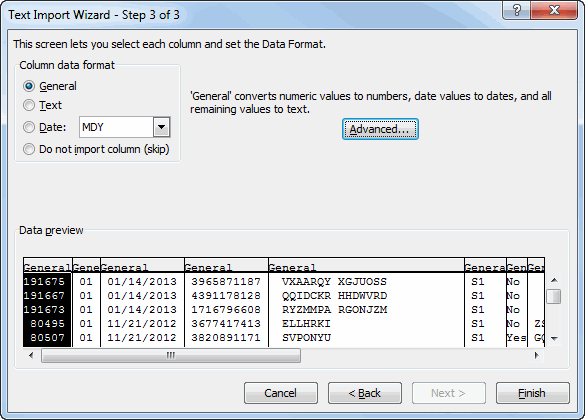
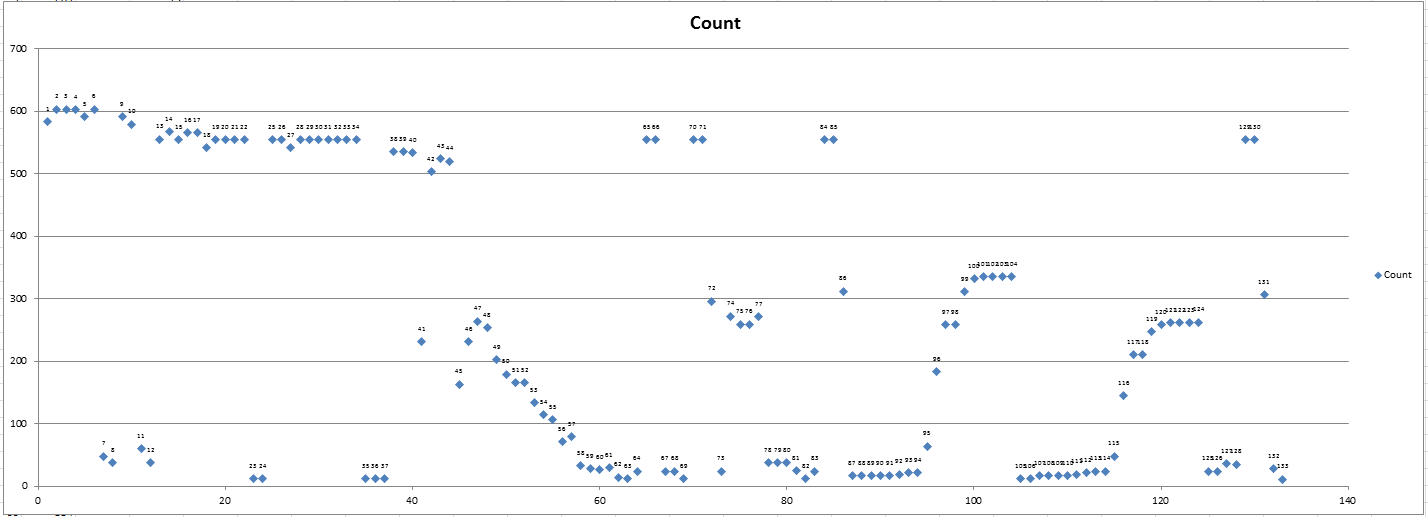
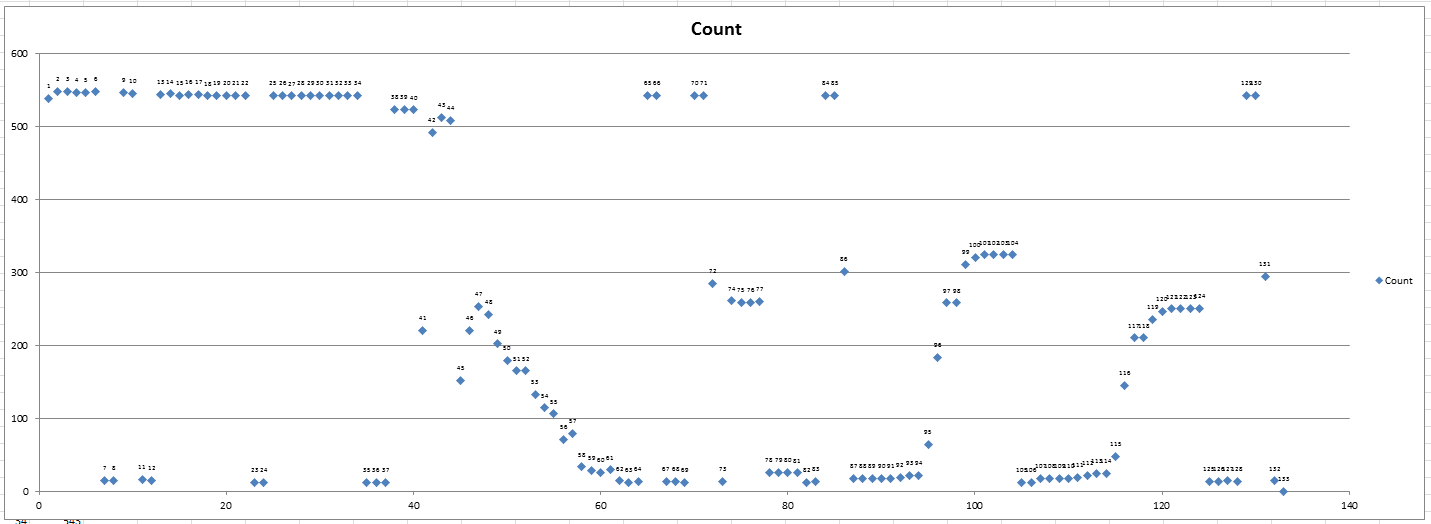
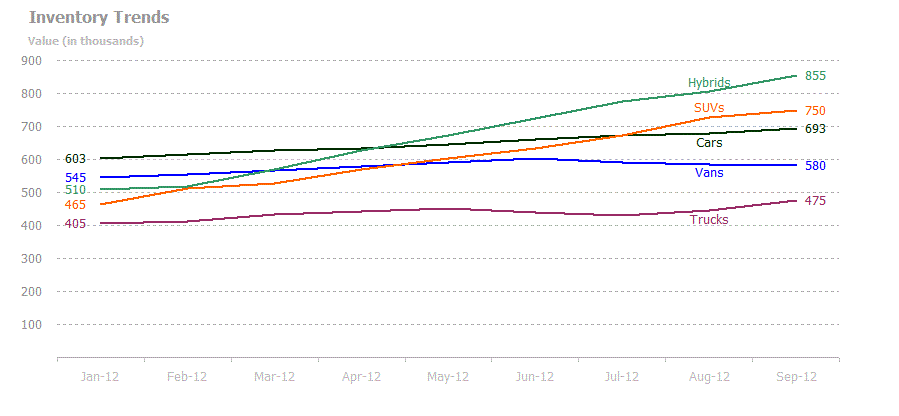
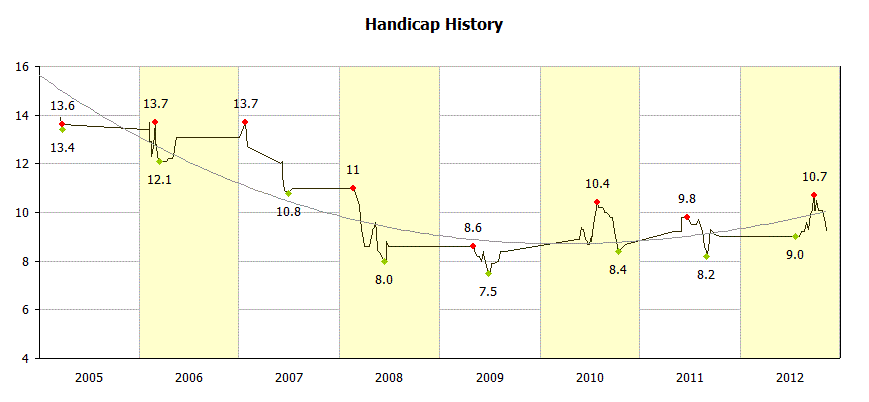
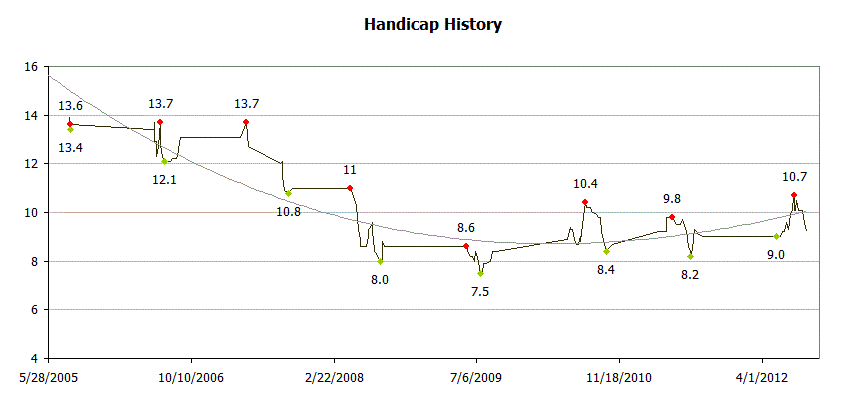
Public Sub LabelInventoryChart()
Dim cht As Chart
Dim srsType As Series
Dim aPoints() As Double
Dim i As Long, j As Long
Dim lTempSrs As Long, dTempVal As Long
Const lLBLOFFSET As Long = 7 'how far away the label is from the line
Const lPNTOFFSET As Long = 1 'which data point to put the series name on (from right)
'Get the chart and dim an array to hold the values at the
'data point
Set cht = wshInventory.ChartObjects(1).Chart
ReDim aPoints(1 To cht.SeriesCollection.Count, 1 To 2)
'Loop through the series and fill an array with the data point
'values
For Each srsType In cht.SeriesCollection
With srsType
If .Points.Count > lPNTOFFSET Then
aPoints(srsType.PlotOrder, 1) = srsType.PlotOrder
aPoints(srsType.PlotOrder, 2) = srsType.Values(.Points.Count - lPNTOFFSET)
End If
End With
Next srsType
'Sort the array on the values - descending
For i = LBound(aPoints, 1) To UBound(aPoints, 1) - 1
For j = i To UBound(aPoints, 1)
If aPoints(i, 2) < aPoints(j, 2) Then
lTempSrs = aPoints(i, 1)
dTempVal = aPoints(i, 2)
aPoints(i, 1) = aPoints(j, 1)
aPoints(i, 2) = aPoints(j, 2)
aPoints(j, 1) = lTempSrs
aPoints(j, 2) = dTempVal
End If
Next j
Next i
'Loop through the series and show data labels
For i = LBound(aPoints, 1) To UBound(aPoints, 1)
Set srsType = cht.SeriesCollection.Item(aPoints(i, 1))
With srsType
If .Points.Count > lPNTOFFSET Then
With .Points(.Points.Count - lPNTOFFSET)
'Create a value label, change the text to the series name, and
'change the color to match the line
.ApplyDataLabels xlDataLabelsShowValue, False, True
.DataLabel.Text = srsType.Name
.DataLabel.Font.Color = srsType.Border.Color
'The data label for the top line goes on top
If i = LBound(aPoints, 1) Then
.DataLabel.Position = xlLabelPositionAbove
.DataLabel.Top = .DataLabel.Top + lLBLOFFSET
'The data label for the lowest line goes on the bottom
ElseIf i = UBound(aPoints, 1) Then
.DataLabel.Position = xlLabelPositionBelow
.DataLabel.Top = .DataLabel.Top - lLBLOFFSET
Else
'Figure out if above or below has more space and put the
'data label where there's the most room
If Abs(aPoints(i, 2) - aPoints(i - 1, 2)) < Abs(aPoints(i, 2) - aPoints(i + 1, 2)) Then
.DataLabel.Position = xlLabelPositionBelow
.DataLabel.Top = .DataLabel.Top - lLBLOFFSET
Else
.DataLabel.Position = xlLabelPositionAbove
.DataLabel.Top = .DataLabel.Top + lLBLOFFSET
End If
End If
End With
End If
'Show data labels for starting and ending data
With .Points(1)
.ApplyDataLabels xlDataLabelsShowValue, False, True
.DataLabel.Position = xlLabelPositionLeft
.DataLabel.Font.Color = srsType.Border.Color
End With
With .Points(.Points.Count)
.ApplyDataLabels xlDataLabelsShowValue, False, True
.DataLabel.Position = xlLabelPositionRight
.DataLabel.Font.Color = srsType.Border.Color
End With
End With
Next i
End Sub