As posted on my blog a few days earlier,
Back in 2005, I noticed something that worried me.
You may know already that switching Application.Calculation to xlCalculationManual can make various code run faster. It can be a big time saver.
The problem, as I see it, is not switching it back to xlCalculationAutomatic. Given that some people for whatever reasons might use Manual Calculation all the time, most people don’t, especially the vast majority of average users who probably haven’t heard of this setting. With Calculation still set to Manual, they might be looking at values that haven’t be updated. Even experienced programmers might be temporarily confused until they figure out what’s going on. Imagine someone in a sales department quoting incorrect pricing to a customer or doing a faulty presentation at an important meeting. Not good.
And now for what really worries me – saving files with this setting. Let’s try something. Close all Excel files, except one to use for testing. Now switch to Manual Calculation. If you don’t know how to do it in code, you can click Calculation Options on the Formulas tab, then select Manual. Now save in that setting, close Excel, and reopen the file. If that file is the first one to be opened, Excel Calculation will be set to Manual by default, and all other files opened thereafter will be affected too. Save any of them with this setting, and the same thing will happen if they happen to be the first file opened…
So, how do you know Calculation is set to Manual without specifically checking?
You can’t. (Actually there is a way to make it more obvious. See the comment from Jake Collins)
Now, imagine sending one of these files to colleagues or customers, then realizing something is amiss days later. Again, not good. In fact, downright scary.
So, also in 2005(?), I made an addin called Calculation Checker. It checks Calculation when you save and prompts you to do so as Automatic if set as otherwise (including Automatic Except for Data Tables).
I’ve found it useful, but since then I’ve thought there’s room for improvement, so I made something new.
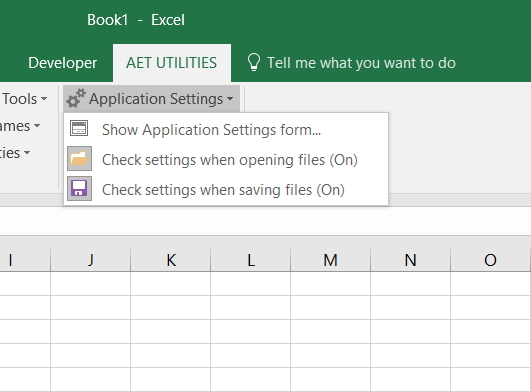
As you can see there’s 3 menu items. The bottom 2, when toggle to “On”, check files when opened/saved for the following settings.
Application.DisplayFormulaBar
Application.DisplayStatusBar
Application.Calculation
Application.ReferenceStyle
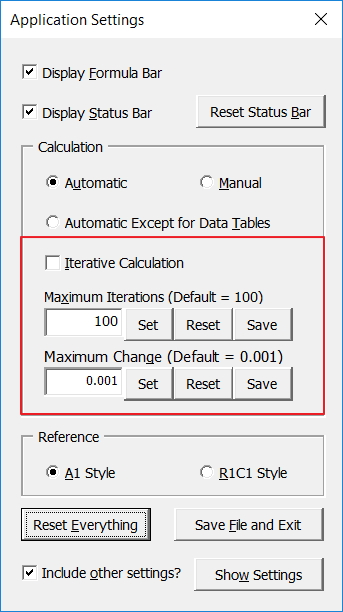
If any of those settings are not at their default, the Application Settings form will be displayed. Non-default settings are displayed in red. (Yes, the first 3 should be obvious, but easy enough to miss if you’re busy, tired or both!)
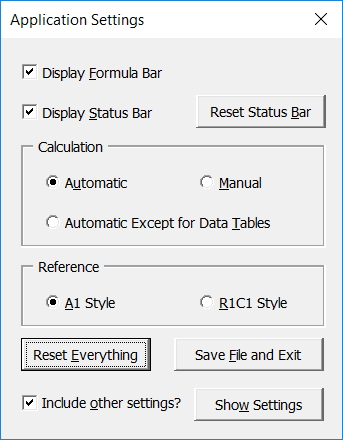
Click the form’s controls to reset them individually, or just click the Reset Everything button, then the Save File and Exit button if you choose to. Alternatively, click the X button not to save the file. Note that any other file that are open will also be saved with these settings (unless you change them later), because they are Application settings, not Workbook settings.
And because the form can be opened directly from the Ribbon, you can easily change any of the settings at any time for whatever reason. Click the Show Settings button and you can see other settings that can also be reset when clicking the Reset Everything button, if the Include other settings checkbox is ticked.
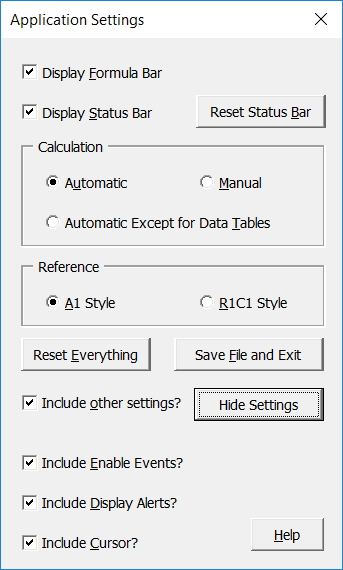
Note
Keep in mind that these additional settings aren’t checked automatically. The form only resets them if you click the Reset Everything button as mentioned above. Also, if Application.EnableEvents is set to False by VBA code, my addin won’t check files when opening or saving as these are the events that trigger it. In fact, you should be setting this False if any of your code does open or save workbooks to prevent my code from running, then set it back to True before the code ends.
Hopefully this tool will be of use. You can download it here.
PS. I’m going on holidays for a few days so I’ll reply to comments (if there be any!) when I get back.