I’ve been working with fixed width text files quite a bit lately. The built-in method for importing these files is terrible. First, it’s yet another wizard and I think it would be better as a single form (but then I think everything is better as a single form). The worst part, by far, is the tiny window that shows a preview of your data.
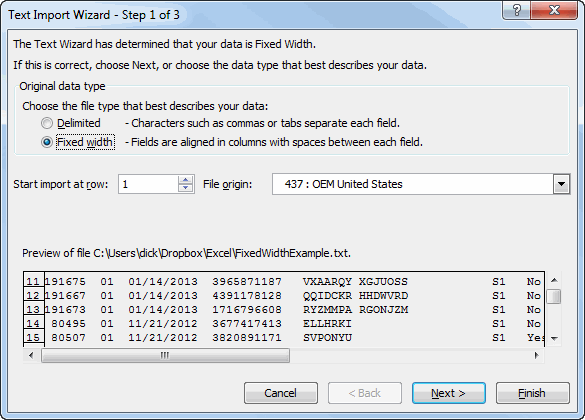
After a few days of using this wizard, it was pretty obvious that I was going to write my own, if for no other reason than to make that window bigger. My importer would be significantly different than Excel’s. Microsoft has to make their method flexible and universal, but I don’t. I know certain things about my text files and can build in some assumptions to make things better. For one, my files have repeating page headers. While Excel allows you to start your import at something other than first row to skip all that crap, it doesn’t do me any good because there’s just more crap to come.
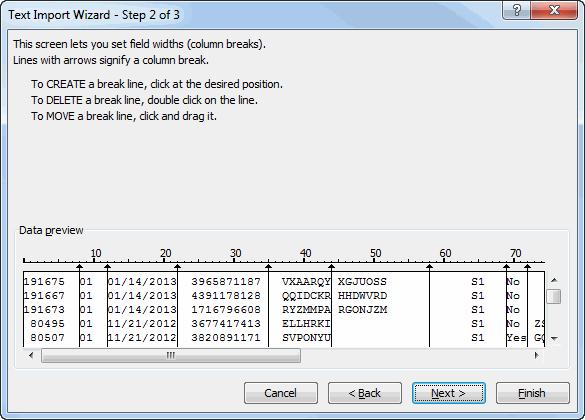
Step 2 of the wizard allows you to add, delete, and move the dividing lines that delineate your columns. I find that Excel does a pretty poor job at placing these lines. But I grant that I haven’t used this on a wide variety of files so it’s entirely possible that their algorithm is the best – it’s just not the best for the types of files I’m using.
Did you think I was going to blow by this step without commenting on the lack of keyboard support? Not a chance. To move the lines, click them and drag them. To add a line, single click. To delete a line, double click. Actually, to delete a line, double click next to the line you want to delete, then double click that new line to delete it, then carefully double click on the original line to delete it. You know what I’m talking about. Click, click, click. Where’s the keyboard love?
The lack of large enough preview window really hurts on this step. I’ll discuss determining where the column lines should go later in this post. Normally after step 2, I just hit finish. But let’s take a look at the last step anyway.
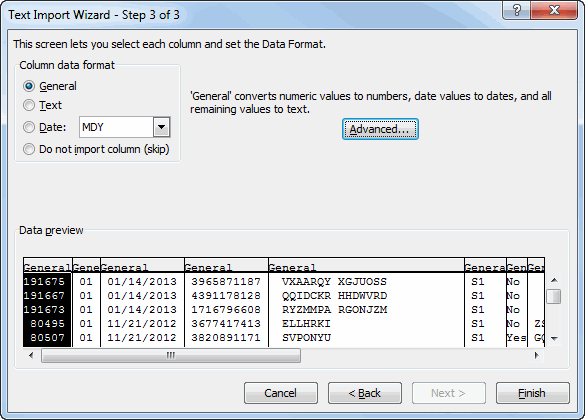
I don’t use this step much because the defaults are really good. As much as I don’t like wizards, I have to give MS props for putting a Finish button on step 2 so I can skip step 3. Now that you’ve defined your columns, this step allows you to specify a data type. The General type works well for most situations, but if you have some text that happens to look like a number, it’s best to set the column to the Text format.
Under the Advanced button, you can switch what decimals and commas mean and, most importantly to me, tell it how to handle trailing minus signs.
So back to how nothing’s ever good enough and I can do everything better. I’m only dealing with fixed width files and I’m always starting on the first row, so step 1 of the wizard is gone. Step 2 and 3 could be combined, I think. It should draw a combobox over each column that let’s you choose the format. When you add or delete columns, it redraws the boxes. The best use of resources is getting the columns right in the first place. If you don’t have to move columns because it guesses so well, then the whole thing becomes a breeze.
Let’s look at this sample file in terms of columns. In order to get all the numbers to show, this chart is kind of big.
I wrote a little macro to analyze the file and report how many characters are in each column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
Sub ReadTextFile() Dim sFile As String Dim lFile As Long Dim sInput As String Dim vaLines As Variant Dim i As Long, j As Long Dim aChars() As Long Dim bLow As Boolean sFile = "C:\Users\dkusleika\Dropbox\Excel\FixedWidthExample.txt" lFile = FreeFile Open sFile For Input As lFile sInput = Input$(LOF(lFile), lFile) Close lFile vaLines = Split(sInput, vbNewLine) ReDim aChars(1 To Len(vaLines(0)) + 1, 1 To 1) For i = LBound(vaLines) To UBound(vaLines) For j = 1 To Len(vaLines(i)) If Mid$(vaLines(i), j, 1) <> Space$(1) Then aChars(j, 1) = aChars(j, 1) + 1 End If Next j Next i Sheet1.Range("B2").Resize(UBound(aChars, 1), 1).Value = aChars End Sub |
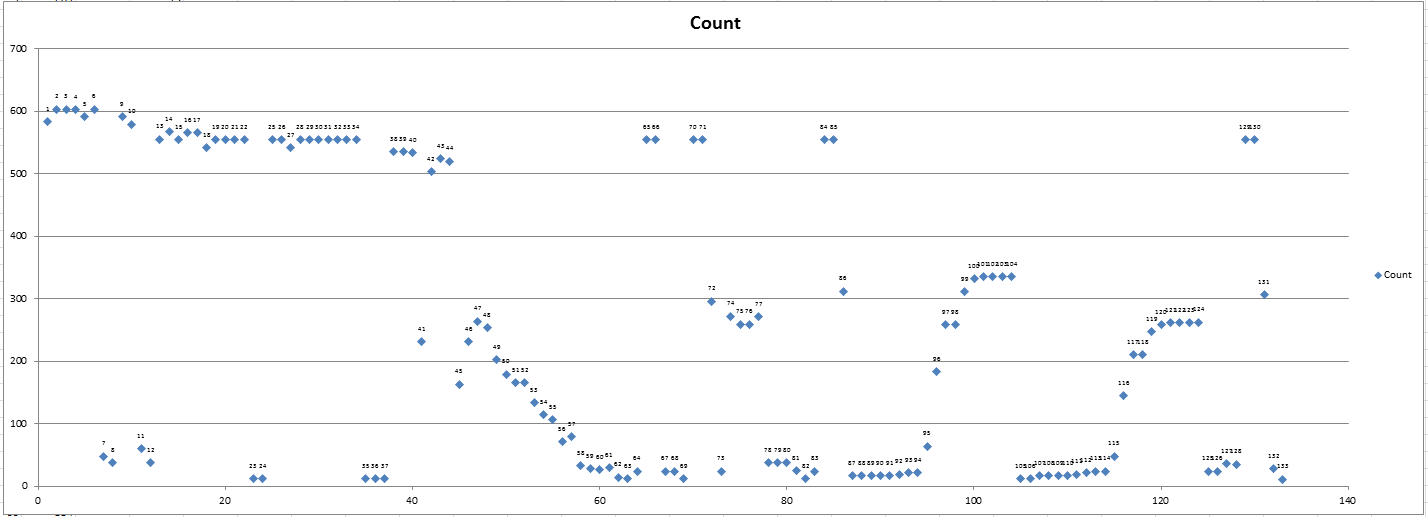
Then I charted them. It seems pretty clear that there’s a break around 7, 12, 23, and 35. The points at 41 and 45 are a little less clear, but starting at 47, you see a clear downward trend. This is the tell-tale sign of left-justified text. Similarly, 87-104 is a right-justified number. The headers muddy up the waters a bit because they contain data that’s no good to me, but still adds to the character count. As I mentioned before, I’m not building a general-purpose solution and it just so happens I can remove the headers. So I did.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
Sub ReadTextFileNoHeaders() Dim sFile As String Dim lFile As Long Dim sInput As String Dim vaLines As Variant Dim i As Long, j As Long Dim aChars() As Long Dim bHeader As Boolean sFile = "\\99991-dc01\99991\dkusleika\My Documents\FixedWidthExample.txt" lFile = FreeFile Open sFile For Input As lFile sInput = Input$(LOF(lFile), lFile) Close lFile vaLines = Split(sInput, vbNewLine) ReDim aChars(1 To Len(vaLines(0)) + 1, 1 To 1) For i = LBound(vaLines) To UBound(vaLines) If Len(vaLines(i)) > 0 Then If Asc(Left$(vaLines(i), 1)) = 12 Then bHeader = True ElseIf vaLines(i) = String(132, "-") Then bHeader = False End If End If If Not bHeader Then For j = 1 To Len(vaLines(i)) If Mid$(vaLines(i), j, 1) <> Space$(1) Then aChars(j, 1) = aChars(j, 1) + 1 End If Next j End If Next i Sheet3.Range("B2").Resize(UBound(aChars, 1), 1).Value = aChars End Sub |
The ASCII code for the page break character is 12. All of my headers end in a string of 132 dashes. That’s damn convenient. Look what happens when I remove the headers.
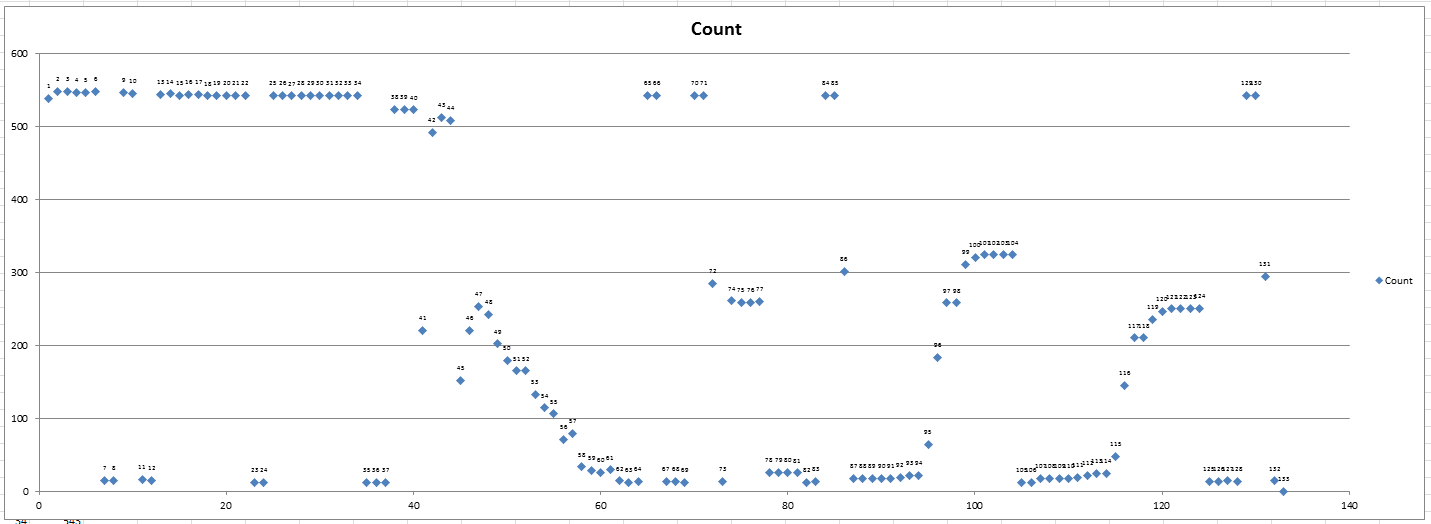
Based on that, I think I could predict the column breaks perfectly. But there’s one aspect of this file that allows me to say that. I don’t have any truly variable length, left-justified text followed by any truly variable length, right-justified number. For instance, if the description column was immediately followed by the debit column, it might be difficult to determine exactly where to break it.
How did I solve that problem? I didn’t. This is as far as I got writing my own text import wizard. Out of nowhere, I read something about reading text files with ADO and all my problems were solved. I had used external data tables to read text files, but never ADO. I’ll post about how I’m importing text files with ADO in my next post.
Posting code? Use <pre> tags for VBA and <code> tags for inline.