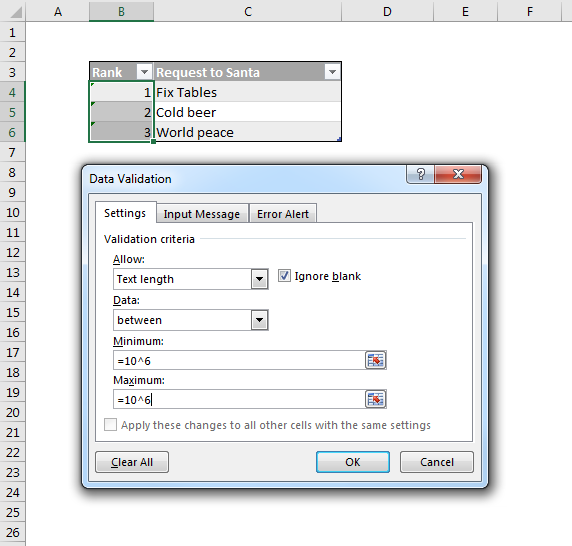
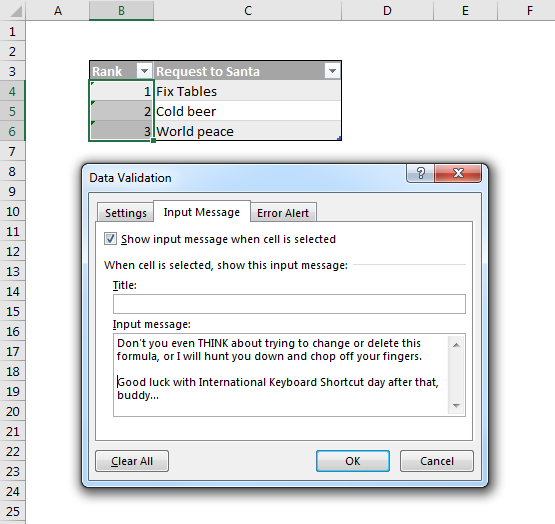
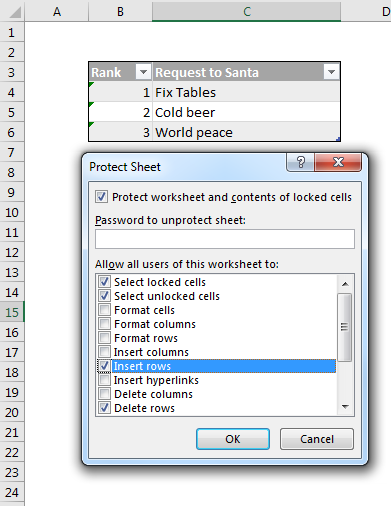
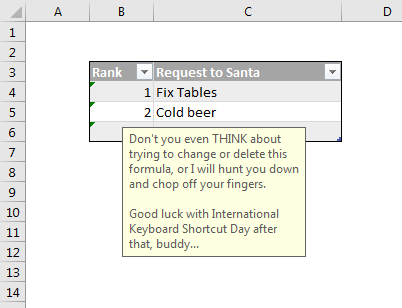
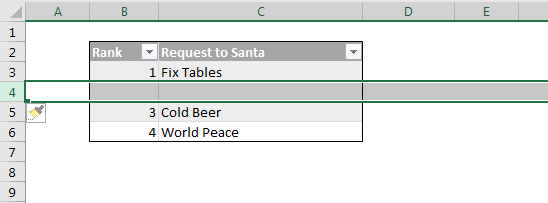
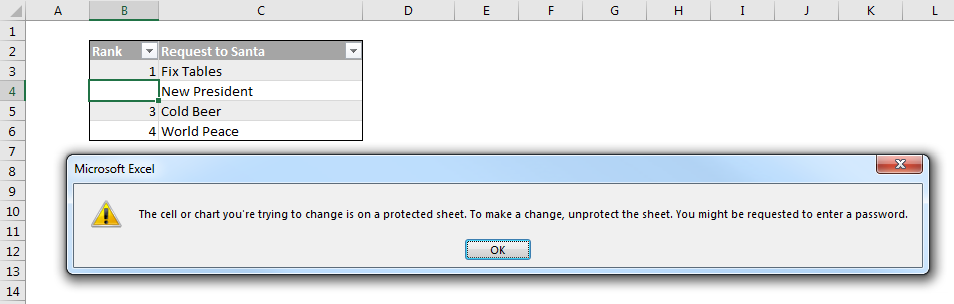
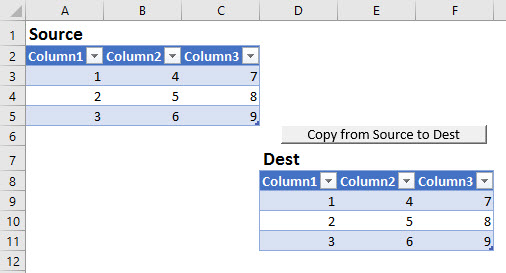
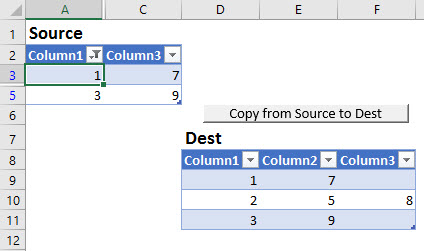
Excel occupies a special place in my heart. It also occupies a special place in the Power universe thanks to the superpowers (DAX and PowerQuery) it shares with its alter-ego PowerBI. Unfortunately this Power Universe is a lot like the Marvel one: An ever-expanding cast of new players with sometimes overlapping powers constantly has me saying “Wait, what?” Characters like Flow and PowerApps among others. Where did they come from? What are their powers? How do they fit into this picture?
Which is why I’m planning on attending the Australia Summit for Microsoft Business Applications in Melbourne from 21st-23rd August. Even though it’s 2,571 km from Wellington. Even though I have to get up at 4am to catch a 6am flight to it. Even though I won’t get to go to work for a few days.

If you live in Australia or New Zealand, you should check out the content on offer for the ‘Power Platform’ track: There is a tonne of presentations that are directly relevant to DAX and PowerQuery for starters. Which means they are directly relevant to Excel Developers too. Particularly so if you’ve come to the conclusion that the only good formula is a DAX formula; and that the argument between VLOOKUP and INDEX/MATCH – or even between Option Explicit vs “ ” – are now pretty much irrelevant, given what we should instead be fighting about is “Should I handle this with PowerQuery, or PowerPivot?”
There’s also a lot of content pitched at Citizen Developers. Citizen what? Well, the Power universe is expanding so fast that Microsoft have decided to let anybody who knows how to drive a mouse program these tools. Granted, not all of us can. Yes, maybe they’re overselling it. But if so, organizations are certainly overbuying, meaning there is a ton of opportunity out there for anyone who can talk the talk, even if they’re still learning to walk the walk.
This conference is a great place to get up to speed on what’s going on in the wider realm that Excel inhabits. But the problem with any conference is scheduling clashes. Sticking with my movie analogy a little longer, it’s like the annual Wellington International Film Festival: It comes around once per year; I always have great intentions to map out my viewing ahead of time when flicking through the glossy programme, but everything I’m interested in seems to be on at the exact same time. Meaning paralyzing indecision and crushing FOMO.
But not this time. This time I have a plan. This time I have carefully studied every presentation outline, and scored each based on a highly scientific method in order to optimize my learning given the inevitable scheduling clashes. And I’m gonna share it with you, in case you want to tag along and sit beside me right at the front center. (Best place to sit. Most of these presenters can’t throw a free T-shirt for crap).
Wednesday 21 August
Creating and Managing a Power BI Enterprise Deployment (Craig Bryden). Why: Craig came to my house last time he was in Wellington. I liked his music. He liked my beer. I need to find out where he’s staying so he can like my music and I can like his beer.
Many to Many and Weak Relationships in Power BI (Matt Allington). Why: I’ve had many weak relationships over the years, and a complete absence of many to many ones. I’ve simply got to find out where I’m going wrong.
Build Flows Like a Coder Without Knowing How to Code (Leon Tribe). Why: I’m clueless. And lazy. And want to embellish my CV.
Thursday 22 August
Using Microsoft Flow as a middleware to turbo-boost PowerBI (John Liu). Why: The title reminds me of Knight Rider. That said, I like the sound of The Shortfall of Microsoft Flow and the Solution No One Talks About (Aung Khaing). So tough choice, but I’ll probably just go with whatever presenter looks most like David Hasselhoff.
Fifteen Examples how Power BI is enabling Local Government to become data-driven (Warren Dean). Why: It’s about the city of Casey. I went to school with Casey. He could hardly find his own house. I never dreamed he would go on to found a city.
Top 5 DAX Tricks for Super Effective Power BI Dashboards (Andrej Lapajne) Why: Zebra BI take their dashboard visualisation principles seriously. And I’m serious about DataViz. That said, I’m also keen on Solving Business Problems with DAX (Darren Gosbell), because I live for examples and problems, having been one and/or the other many times over.
Friday 23 August
Debugging Power BI Performance Issues (Darren Gosbell) Why: I’ve had performance issues in the past. Ask anyone. Mind you, Darren is on at the same time as Bhavik Merchant from Microsoft, who’s giving us Power BI Performance Tuning: What, Why and When? They should make these guys do a performance-off.
Unleash Row Level Security Patterns in Power BI (Reza Rad) Why: Because I’m insecure and prone to oversharing.
Learning M from the UI (Matt Allington) Why: I want to see what M stands for, and what it has to do with Unemployment Insurance.
Advanced Analytics Methods To Uncover Hidden Gems in Your Data (Martin Kratky) Why: Because I’m constantly regressing (I’d go to see Phil Seamark talk about The Art of Data Modelling with Analysis Services, but he runs the Wellington PowerBI User Group with me, so I’ll just make him give the presentation there, while I scarf free Pizza).
So, that’s my highly scientific method. And I think it’s as good a method as any.
Mind you, there’s a hell of a lot of other great looking presentations with less funny titles that I’m bypassing. Again, check out the Power Platform track on the website, or alternately click here for a handy Word doc I compiled contains the presentation outlines of a whole bunch of sessions that I’d recommend might be of interest to Excel folk.
Love to see you there.