Jeff here again. I had a crack at rewriting my Unpivot via SQL routine, to see if I could make it simpler and faster. The point of the routine is to let you turn a very large cross-tab directly into a PivotTable in the case that a flat file would be too long to fit in Excel’s grid. The original routine works by making a temp copy of the file (to avoid Memory Leak) and then doing lots and lots of UNION ALLs against that temp copy to unwind it one cross-tab column at a time. (The reason we need those UNION ALLs is that there is no UNPIVOT command in the pigeon English dialect of SQL that Excel and Access speak.) My routine then executes the SQL via ADO, and creates a Pivot directly out of the resulting RecordSet.
So if we had a data set that looked like this:
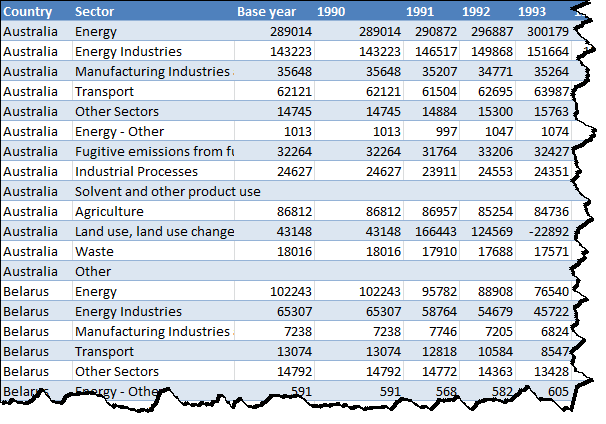
…then the resulting SQL looks something like this:
SELECT [Country], [Sector], [Base year (Convention)], [1990] AS Total, '1990' AS [Year] FROM [Data$A18:H28]
UNION ALL SELECT [Country], [Sector], [Base year (Convention)], [1991] AS Total, '1991' AS [Year] FROM [Data$A18:H28]
UNION ALL SELECT [Country], [Sector], [Base year (Convention)], [1992] AS Total, '1992' AS [Year] FROM [Data$A18:H28]
UNION ALL SELECT [Country], [Sector], [Base year (Convention)], [1993] AS Total, '1993' AS [Year] FROM [Data$A18:H28]
UNION ALL SELECT [Country], [Sector], [Base year (Convention)], [1994] AS Total, '1994' AS [Year] FROM [Data$A18:H28]
But as per my previous post, the code to accomplish this is pretty long. This is partly because the Microsoft JET/ACE Database engine has a hard limit of 50 ‘UNION ALL’ clauses, which you will soon exceed if you have a big cross-tab. I get around this limit by creating sub-blocks of SELECT/UNION ALL statements under this limit, and then stitching these sub-blocks with an outer UNION ALL ‘wrapper’. But that results in fairly complicated code and presumably quite a bit of work for the JET/ACE driver.
So I got to thinking that rather than using all those UNION ALLs to create the RecordSet with SQL, why not just populate a disconnected RecordSet directly from an amended version of snb’s elegant code, like so:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
Sub UnPivotViaRecordset(rngCrosstab As Range, rngLeftHeaders As Range, rngRightHeaders As Range, strCrosstabName As String) Dim rs As Object 'We're using late binding. If we were using early, we'd use Dim rs ADODB.Recordset Dim pc As PivotCache Dim pt As PivotTable Dim wks As Worksheet Dim rng As Range Dim lngRecords As Long Dim timetaken As Date Dim cell As Range Dim varSource As Variant Dim lRightColumns As Long Dim lLeftColumns As Long Dim j As Long Dim n As Long Dim m As Long Dim i As Long timetaken = Now() On Error GoTo 0 Set rs = CreateObject("ADODB.Recordset") With rs For Each cell In rngLeftHeaders .Fields.append cell.Value, adVarChar, 150 Next cell .Fields.append strCrosstabName, adVarChar, 150 .Fields.append "Value", adDouble .CursorLocation = adUseClient .CursorType = 2 ' adLockPessimistic .Open varSource = rngCrosstab lRightColumns = rngRightHeaders.Columns.Count lLeftColumns = UBound(varSource, 2) - lRightColumns lngRecords = (UBound(varSource) - 1) * lRightColumns For j = 1 To lngRecords m = (j - 1) Mod (UBound(varSource) - 1) + 2 n = (j - 1) \ (UBound(varSource) - 1) + lLeftColumns + 1 .addnew i = 1 For Each cell In rngLeftHeaders .Fields(cell.Value) = varSource(m, i) i = i + 1 Next cell .Fields(strCrosstabName) = varSource(1, n) .Fields("Value") = varSource(m, n) Next j .movefirst Set wks = Sheets.Add Set rng = wks.Range("A1") Set pc = ActiveWorkbook.PivotCaches.Create(xlExternal) Set pc.Recordset = rs Set pt = pc.CreatePivotTable(TableDestination:=rng) 'Clean Up rs.Close Set rs = Nothing End With timetaken = timetaken - Now() Debug.Print "UnPivot: " & Now() & " Time Taken: " & Format(timetaken, "HH:MM:SS") End Sub |
This routine worked fine on a small number of records. For instance, it unwound a cross-tab of 1000 rows x 100 cross-tab columns = 100,000 records in 8 seconds. Not exactly lightning, but it got there.
But it did not work fine on larger ones: at around 2500 rows x 100 cross-tab columns = 250,000 records it returned an Out of Memory error. So that rules the Disconnected RecordSet approach out for unwinding super-size cross-tabs. Unless you’re manipulating small data sets, steer clear of disconnected RecordSets.
Not to be deterred, I thought I’d try a different approach: I amended snb’s original approach so that it split a large flat file across multiple tabs in need, and then wrote a seperate routine to mash together the data in those tabs with SQL. This will result in far fewer UNION ALL’s (one per sheet) than my original code (one per column), and hopefully much faster performance.
Here’s how I revised SNB’s code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
Sub UnPivot_MultipleTabs(rngCrosstab As Range, _ rngLeftHeaders As Range, _ rngRightHeaders As Range, _ strCrosstabName As String) Dim varSource As Variant Dim lRecords As Long Dim lPass As Long Dim lPasses As Long Dim lArrayLength As Long Dim lLeftColumns As Long Dim i As Long Dim j As Long Dim k As Long Dim m As Long Dim n As Long Dim wksNew As Worksheet Dim timetaken As Date timetaken = Now() varSource = rngCrosstab lRecords = Intersect(rngRightHeaders.EntireColumn, rngCrosstab).Cells.Count lPasses = Application.RoundUp(lRecords / Application.Rows.Count, 0) lLeftColumns = rngLeftHeaders.Columns.Count ReDim strWorksheets(1 To lPasses) For lPass = 1 To lPasses If lPass = lPasses Then 'The last pass will have a smaller output array lArrayLength = (UBound(varSource) - 1) * rngRightHeaders.Columns.Count - (lPasses - 1) * (Application.Rows.Count - 1) Else: lArrayLength = Application.Rows.Count - 1 End If ReDim varOutput(1 To lArrayLength, 1 To lLeftColumns + 2) For j = 1 To UBound(varOutput) m = ((lPass - 1) * (Application.Rows.Count - 1) + j - 1) Mod (UBound(varSource) - 1) + 2 ' Why +2 above? ' Because + 1 accounts for the fact that x mod x is zero, but we are using 1-based arrays so must add one ' And the other + 1 accounts for headers n = ((lPass - 1) * (Application.Rows.Count - 1) + j - 1) \ (UBound(varSource) - 1) + lLeftColumns + 1 varOutput(j, lLeftColumns + 1) = varSource(1, n) varOutput(j, lLeftColumns + 2) = varSource(m, n) For i = 1 To lLeftColumns varOutput(j, i) = varSource(m, i) Next i Next j Set wksNew = Worksheets.Add strWorksheets(lPass) = wksNew.Name With Cells(1, 1) .Resize(, lLeftColumns).Value = rngLeftHeaders.Value .Offset(, lLeftColumns).Value = strCrosstabName .Offset(, lLeftColumns + 1).Value = "Value" .Offset(1, 0).Resize(UBound(varOutput), UBound(varOutput, 2)) = varOutput End With Next lPass timetaken = timetaken - Now() Debug.Print "UnPivot: " & Now() & " Time Taken: " & Format(timetaken, "HH:MM:SS") End Sub |
That part works a treat. Takes around 38 seconds to take a 19780 Row x 100 Column crosstab = 1,977,900 records and spit it out as a flat file in two sheets.
And here’s the code that stiches those together into one PivotTable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
Sub PivotFromTabs(ParamArray strSheetNames() As Variant) Dim cell As Range Dim wksSource As Worksheet Dim pt As PivotTable Dim rngCurrentHeader As Range Dim timetaken As Date Dim strMsg As String Dim varAnswer As Variant Dim strWorksheets() As String Dim sExt As String Dim sSQL As String Dim arSQL() As String Dim arTemp() As String Dim sTempFilePath As String Dim objPivotCache As PivotCache Dim objRS As Object Dim oConn As Object Dim sConnection As String Dim wksNew As Worksheet ''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ' When using ADO with Excel data, there is a documented bug ' causing a memory leak unless the data is in a different ' workbook from the ADO workbook. ' http://support.microsoft.com/kb/319998 ' So the work-around is to save a temp version somewhere else, ' then pull the data from the temp version, then delete the ' temp copy ''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' sTempFilePath = ActiveWorkbook.Path If Application.Version >= 12 Then 'use ACE provider connection string 'sTempFilePath = sTempFilePath & "\" & "TempFile_223757" & ".xlsx" sTempFilePath = sTempFilePath & "\" & "TempFile_" & Format(time(), "hhmmss") & ".xlsx" sConnection = "Provider=Microsoft.ACE.OLEDB.12.0; Data Source=" & sTempFilePath & ";Extended Properties=""Excel 12.0;IMEX=1;HDR=Yes"";" Else: 'use JET provider connection string sTempFilePath = sTempFilePath & "\" & "TempFile_" & Format(time(), "hhmmss") & ".xls" sConnection = "Provider=Microsoft.Jet.OLEDB.4.0; Data Source=" & sTempFilePath & ";Extended Properties=""Excel 8.0;HDR=Yes"";" End If ActiveWorkbook.SaveCopyAs sTempFilePath Set objRS = CreateObject("ADODB.Recordset") Set oConn = CreateObject("ADODB.Connection") sSQL = "SELECT * FROM [" & Join(strSheetNames, "$] UNION ALL SELECT * FROM [") & "$]" Debug.Print sSQL ' Open the ADO connection to our temp Excel workbook oConn.Open sConnection ' Open the recordset as a result of executing the SQL query objRS.Open Source:=sSQL, ActiveConnection:=oConn, CursorType:=1 Set objPivotCache = ActiveWorkbook.PivotCaches.Create(xlExternal) Set objPivotCache.Recordset = objRS Set wksNew = Sheets.Add Set pt = objPivotCache.CreatePivotTable(TableDestination:=wksNew.Range("A3")) 'cleanup Set objPivotCache = Nothing objRS.Close oConn.Close Set objRS = Nothing Set oConn = Nothing Kill sTempFilePath End Sub |
I tested this routine on some sheets with smaller datasets in them initially. Works just fine.
200,000 records in 2 sheets, no problem
But on bigger stuff, weirdsville:
For instance, here’s what I got when I tried to run it on 250,000 records split across two sheets:
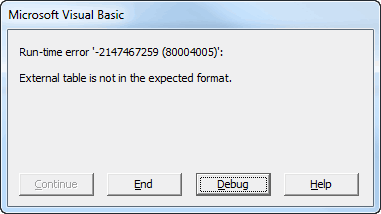
What do you mean, “External table is not in the expected format“? It was just a minute ago!
Pushing debug shows that the oConn.Open sConnection line is highlighted. When I pushed F5 then the code ran without hitch, and produced the pivot as expected. So who knows what that was about.
But when I tried it on a larger dataset of 600,000 records in each sheet, I got an ‘Unexpected error from external database driver (1)’ message:
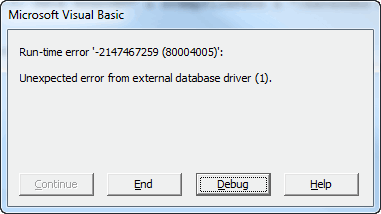
You betcha it’s unexpected! Googling didn’t turn up much, apart from some people having issues trying to get very big datasets from Excel into SQL Server. One person’s problem was solved by adding in imex=1 in the connection string, but it didn’t do anything for me.
I tried running the sub on several sheets with various amounts of records in each. About the maximum I could pull through was 3 sheets of 400,000 rows. But anything bigger, then I got that Unexpected Error From External Database Driver error again.
Next I tried running the code on just one sheet with various rows of data in it, to see what happened. After I push F5 to ignore the External Table Is Not In The Expected Format error, it did manage to produce a pivot in all cases, but the pivot may or may not contain all the data, depending on how many records were in the source sheet. For instance:
- If there’s 500,000 records in the flat file I 500,000 records in the pivot.
- If there’s 750,000 records in the flat file I only 613,262 records in the pivot. wtf?
- If there’s 1,000,000 records in the flat file, I 613,262 records in the pivot again. wtfa?
Whereas my original UNPIVOT BY SQL routine could handle much larger datasets than either the disconnected RecordSet approach or the above one without complaining.
Well screw you, code…I’m giving you an error back:
Did you consider ?
– to unpivot the crosstab into a string
– save that string to a csv-file
– import that string into an access db
– create a privottable in Excel, linked to (based on) the Access DB
Yeah, I thought briefly about saving it to an .accdb file. But I really want something stand-alone that I could distribute easily, and thought that having to rely on having an .accdb file saved somewhere added too much complexity – particularly given that I want to build this into an add-in along with a whole bunch of other pivot-centric routines. That said, now you’ve got me wondering whether your approach might be faster, and whether I can bypass the .accdb file bit altogether and build a pivot directly based on a CSV.
Any thoughts on why my 2nd approach above doesn’t work as expected, snb?
I tried to create a pivottable based on a csv-file. I did’t work.
If I understand Frans Brus’s contribution correctly, it isn’t possible:
http://pixcels.nl/pivottable-data-connection-models/#more-1307
Ah well. Guess I’ll just stick with my complicated UNION ALL method in the rare instances that the crosstab is too big for your much simpler/faster approach.
I wonder why the ADO approach above isn’t working? Very strange that a SELECT ALL does not in fact select all.
Unfortunately we’ll never see the code behind this, but Tableau Software has an unpivot add-in available. It’s meant to clean up data to be used in Tableau itself, but it does the trick. It’s just a regular .xlam file so it may well be just an inefficient set of loops. It’s password protected, so we’ll never know.
http://kb.tableausoftware.com/articles/knowledgebase/addin-reshaping-data-excel
@Zach, according to this SO user, some of the code on this site is “many, many times faster” than the Tableau version: http://stackoverflow.com/questions/18815786/faster-de-pivot-macro?lq=1.
I have a similar problem. I have a dBase file with almost 2 million records. I need write this dBase file into txt file. I was just using vba excel for this. But When it reaches around 1,100,000 records, I receive a out of memory error. In the first line of the subroutine, after openning the file, the recordcount statement already gives a out of memory error. It looks like I can’t read more than the rows limit of a worksheet. But, again, I am not using a worksheet. Just using vba in excel to write a txt file.
Interesting point about 50 UNION ALL clauses: I haven’t met that particular limit.
I met a different limit: “Too many fields defined”
The JET.OLEDB.4.0 drivers have a hard limit of 255 fields across all your UNION clauses: that is to say: you can have twenty-five union clauses returning ten fields each, but not twenty-six of them.
Hi Nigel. These are edge cases. You obviously live on the edge too :-)
Sam advises that fortunately PowerQuery doesn’t suffer from this hard limit in his comment at http://dailydoseofexcel.com/archives/2013/11/19/unpivot-via-sql/#comment-96724 so there’s our escape clause I guess.
I timed my VBA/Array based unpivot from that link against PowerQuery on a dataset that (when unwound) had more than 1,000,000 rows some time back, and found that they both run in the exact same time. I keep meaning to write a post called “If you’re finding VBA slow, then you’re not finding the *right* VBA. “.
Colin Banefield talks about this in his insightful comment at https://www.powerpivotpro.com/2015/04/secret-pot-roast-recipe-power-query-vs-vba-macros/#comment-124541