Howdy folks. Jeff Pivot…err…Weir here again.
Recently Ken Puls did a handy post on how to unpivot data using PowerQuery. Jan Karel commented that you can do this using Multiple Consolidation Ranges. That’s true, but what I like about the PowerQuery approach is that you can translate the currently selected columns into attribute-value pairs, combined with the rest of the values in each row. That is, you can have multiple hierarchical columns down the left of your CrossTab as well as the column headers across the top that you want to amalgamate. Which is great if you have a crosstab like this:
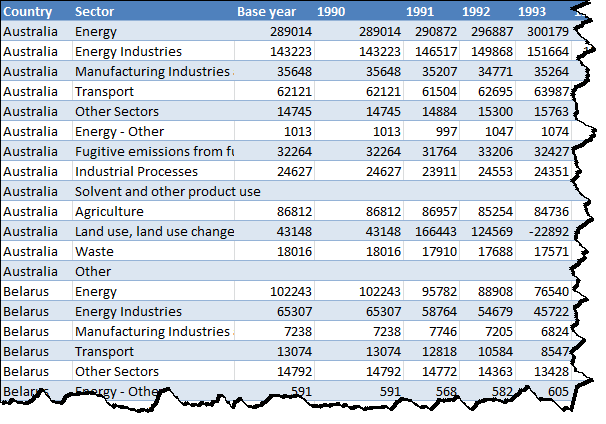
Whereas the Multiple Consolidation trick only handles one column down the left out of the box.
Mike Alexander posted a great bacon-tasting morsel of a trick to get around that issue way back in 2009 when he used to blog. He simply concatenating all the non-column-oriented fields into one dimension field into one temporary column. Check out his post Transposing a Dataset with a PivotTable. But as commenter dermotb said…it’s like a magic spell that you have to write down somewhere, and try to find when you need it, because it’s complex. (I love Mike’s reply to that: Come on. Excel is full of magic syntax, mystical hot keys, and vba voodoo that requires some level of memorizing steps. That’s why I can make a living peddling “tips and tricks”.)
Another problem with the Multiple Consolidation trick is that you might well end up with more data than fits in your sheet, by the time you flatten it out. Especially in old Excel. Because the number of rows you end up with in a flat file is the number of rows you start off with times the number of columns that you’re going to amalgamate. So for say a time-series dataset that covers quite a few items and a reasonable period of time, you could be in trouble.
So a while ago I had a crack at writing a SQL routine that unpivots by doing lots of UNION ALL joins, and writes the data directly to a PivotTable. The UNION ALLs are required because the pidgin English version of SQL that Excel speaks (and Access too, I guess) doesn’t have a UNPIVOT command.
I struck a few hurdles along the way. For instance, it turns out that the Microsoft JET/ACE Database engine has a hard limit of 50 ‘UNION ALL’ clauses, which you will soon exceed if you have a big crosstab with multiple columns down the left. I found a great thread over at MrExcel at which Fazza overcame this hard limit by creating sub-blocks of UNION ALL statements, then stiching them all together with another UNION ALL. Another problem is that SQL didn’t like dates (and sometimes numbers) in the headers. So I turn them into text with an apostrophe.
And another thing I do is save a temp version of the file somewhere, and then query that temp version rather than querying the open workbook. Even though the Memory Leak issue that this avoids has been largely fixed in New Excel, I still found that querying the open book was causing grief occasionally.
Anyway, here’s the result. I’ve turned it into a function, and you can pre-specify inputs if you like. Otherwise you’ll be prompted for the following:
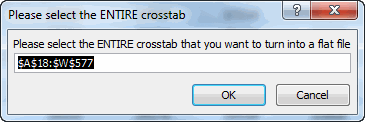
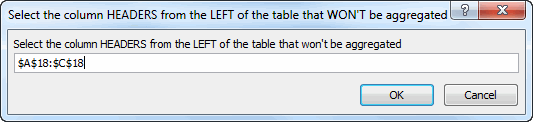
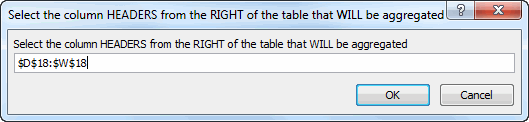

…and then you’ll get a Pivot:

Take it for a spin, let me know of any issues in the comments. Note that I’ve tried to code it to handle Excel 2003 and earlier, but I don’t have old Excel anymore so couldn’t test it. In fact, that’s why the TabularLayout sub is separate – I had to put it in a subroutine because if someone has ‘old’ Excel then the main function wouldn’t compile.
—Edit 11 March 2014—
I’ve updated the below code to incorporate snb’s approach using array manipulation from Unpivot Shootout where possible.
Cheers
Jeff
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 |
Function unpivot(Optional rngCrossTab As Range, _ Optional rngLeftHeaders As Range, _ Optional rngRightHeaders As Range, _ Optional strCrosstabName As String, _ Optional rngOutput As Range, _ Optional bSkipBlanks As Boolean = False) As Boolean ' Desc: Turns a crosstab file into a flatfile using array manipulation. ' If the resulting flat file will be too long to fit in the worksheet, ' the routine uses SQL and lots of 'UNION ALL' statements to do the ' equivalent of the 'UNPfaddIVOT' command in SQL Server (which is not available ' in Excel)and writes the result directly to a PivotTable ' Base code for the SQL UnPivot devived from from Fazza at MR EXCEL forum: ' http://www.mrexcel.com/forum/showthread.php?315768-Creating-a-pivot-table-with-multiple-sheets ' The Microsoft JET/ACE Database engine has a hard limit of 50 'UNION ALL' clauses, but Fazza's ' code gets around this by creating sublocks of up to 25 SELECT/UNION ALL statements, and ' then unioning these. ' Programmer: Jeff Weir ' Contact: weir.jeff@gmail.com ' Name/Version: Date: Ini: Modification: ' UnPivot V1 20131122 JSW Original Development ' Inputs: Range of the entile crosstab ' Range of columns down the left that WON'T be normalized ' Range of columns down the right that WILL be normalize ' String containing the name to give columns that will be normalized ' Outputs: A pivottable of the input data on a new worksheet. ' Example: ' It takes a crosstabulated table that looks like this: ' Country Sector 1990 1991 ... 2009 ' ============================================================================= ' Australia Energy 290,872 296,887 ... 417,355 ' New Zealand Energy 23,915 25,738 ... 31,361 ' United States Energy 5,254,607 5,357,253 ... 5,751,106 ' Australia Manufacturing 35,648 35,207 ... 44,514 ' New Zealand Manufacturing 4,389 4,845 ... 4,907 ' United States Manufacturing 852,424 837,828 ... 735,902 ' Australia Transport 62,121 61,504 ... 83,645 ' New Zealand Transport 8,679 8,696 ... 13,783 ' United States Transport 1,484,909 1,447,234 ... 1,722,501 ' And it returns the same data in a recordset organised like this: ' Country Sector Year Value ' ==================================================== ' Australia Energy 1990 290,872 ' New Zealand Energy 1990 23,915 ' United States Energy 1990 5,254,607 ' Australia Manufacturing 1990 35,648 ' New Zealand Manufacturing 1990 4,389 ' United States Manufacturing 1990 852,424 ' Australia Transport 1990 62,121 ' New Zealand Transport 1990 8,679 ' United States Transport 1990 1,484,909 ' Australia Energy 1991 296,887 ' New Zealand Energy 1991 25,738 ' United States Energy 1991 5,357,253 ' Australia Manufacturing 1991 35,207 ' New Zealand Manufacturing 1991 4,845 ' United States Manufacturing 1991 837,828 ' Australia Transport 1991 61,504 ' New Zealand Transport 1991 8,696 ' United States Transport 1991 1,447,234 ' ... ... ... ... ' ... ... ... ... ' ... ... ... ... ' Australia Energy 2009 417,355 ' New Zealand Energy 2009 31,361 ' United States Energy 2009 5,751,106 ' Australia Manufacturing 2009 44,514 ' New Zealand Manufacturing 2009 4,907 ' United States Manufacturing 2009 735,902 ' Australia Transport 2009 83,645 ' New Zealand Transport 2009 13,783 ' United States Transport 2009 1,722,501 Const lngMAX_UNIONS As Long = 25 Dim varSource As Variant Dim varOutput As Variant Dim lLeftColumns As Long Dim lRightColumns As Long Dim i As Long Dim j As Long Dim m As Long Dim n As Long Dim lOutputRows As Long Dim arSQL() As String Dim arTemp() As String Dim sTempFilePath As String Dim objPivotCache As PivotCache Dim objRS As Object Dim oConn As Object Dim sConnection As String Dim wks As Worksheet Dim wksNew As Worksheet Dim cell As Range Dim strLeftHeaders As String Dim wksSource As Worksheet Dim pt As PivotTable Dim rngCurrentHeader As Range Dim timetaken As Date Dim strMsg As String Dim varAnswer As Variant Const Success As Boolean = True Const Failure As Boolean = False unpivot = Failure 'Identify where the ENTIRE crosstab table is If rngCrossTab Is Nothing Then Application.ScreenUpdating = True On Error Resume Next Set rngCrossTab = Application.InputBox( _ Title:="Please select the ENTIRE crosstab", _ prompt:="Please select the ENTIRE crosstab that you want to turn into a flat file", _ Type:=8, Default:=Selection.CurrentRegion.Address) If Err.Number <> 0 Then On Error GoTo errhandler Err.Raise 999 Else: On Error GoTo errhandler End If rngCrossTab.Parent.Activate rngCrossTab.Cells(1, 1).Select 'Returns them to the top left of the source table for convenience End If 'Identify range containing columns of interest running down the table If rngLeftHeaders Is Nothing Then On Error Resume Next Set rngLeftHeaders = Application.InputBox( _ Title:="Select the column HEADERS from the LEFT of the table that WON'T be aggregated", _ prompt:="Select the column HEADERS from the LEFT of the table that won't be aggregated", _ Default:=Selection.Address, Type:=8) If Err.Number <> 0 Then On Error GoTo errhandler Err.Raise 999 Else: On Error GoTo errhandler End If Set rngLeftHeaders = rngLeftHeaders.Resize(1, rngLeftHeaders.Columns.Count) 'just in case they selected the entire column rngLeftHeaders.Cells(1, rngLeftHeaders.Columns.Count + 1).Select 'Returns them to the right of the range they just selected End If If rngRightHeaders Is Nothing Then 'Identify range containing data and cross-tab headers running across the table On Error Resume Next Set rngRightHeaders = Application.InputBox( _ Title:="Select the column HEADERS from the RIGHT of the table that WILL be aggregated", _ prompt:="Select the column HEADERS from the RIGHT of the table that WILL be aggregated", _ Default:=Selection.Address, _ Type:=8) If Err.Number <> 0 Then On Error GoTo errhandler Err.Raise 999 Else: On Error GoTo errhandler End If Set rngRightHeaders = rngRightHeaders.Resize(1, rngRightHeaders.Columns.Count) 'just in case they selected the entire column rngCrossTab.Cells(1, 1).Select 'Returns them to the top left of the source table for convenience End If If strCrosstabName = "" Then 'Get the field name for the columns being consolidated e.g. 'Country' or 'Project'. note that reserved SQL words like 'Date' cannot be used strCrosstabName = Application.InputBox( _ Title:="What name do you want to give the data field being aggregated?", _ prompt:="What name do you want to give the data field being aggregated? e.g. 'Date', 'Country', etc.", _ Default:="Date", _ Type:=2) If strCrosstabName = "False" Then Err.Raise 999 End If If rngOutput Is Nothing Then 'Identify range containing data and cross-tab headers running across the table On Error Resume Next Set rngOutput = Application.InputBox( _ Title:="Where do you want to output the data", _ prompt:="Select the top left cell where you want the transformed data to be output", _ Default:=Selection.Address, _ Type:=8) If Err.Number <> 0 Then On Error GoTo errhandler Err.Raise 999 Else: On Error GoTo errhandler End If End If timetaken = Now() Application.ScreenUpdating = False 'Work out if the worksheet has enough rows to fit a crosstab in If Intersect(rngRightHeaders.EntireColumn, rngCrossTab).Cells.Count <= Columns(1).Rows.Count Then 'Resulting flat file will fit on the sheet, so use array manipulation. varSource = rngCrossTab lRightColumns = rngRightHeaders.Columns.Count lLeftColumns = UBound(varSource, 2) - lRightColumns If Not bSkipBlanks Then ReDim varOutput(1 To lRightColumns * (UBound(varSource) - 1), 1 To lLeftColumns + 2) Else lOutputRows = Application.WorksheetFunction.CountA(Intersect([appRightHeaders].EntireColumn, rngCrossTab)) - [appRightHeaders].Cells.Count ReDim varOutput(1 To lOutputRows, 1 To lLeftColumns + 2) End If If Not bSkipBlanks Then For j = 1 To UBound(varOutput) m = (j - 1) Mod (UBound(varSource) - 1) + 2 n = (j - 1) \ (UBound(varSource) - 1) + lLeftColumns + 1 varOutput(j, lLeftColumns + 1) = varSource(1, n) varOutput(j, lLeftColumns + 2) = varSource(m, n) For i = 1 To lLeftColumns varOutput(j, i) = varSource(m, i) Next i Next j Else lOutputRows = 1 For j = 1 To Intersect([appRightHeaders].EntireColumn, rngCrossTab).Cells.Count - [appRightHeaders].Cells.Count m = (j - 1) Mod (UBound(varSource) - 1) + 2 n = (j - 1) \ (UBound(varSource) - 1) + lLeftColumns + 1 If Not IsEmpty(varSource(m, n)) Then varOutput(lOutputRows, lLeftColumns + 1) = varSource(1, n) varOutput(lOutputRows, lLeftColumns + 2) = varSource(m, n) For i = 1 To lLeftColumns varOutput(lOutputRows, i) = varSource(m, i) Next i lOutputRows = lOutputRows + 1 End If Next j End If With rngOutput .Resize(, lLeftColumns).Value = rngLeftHeaders.Value .Offset(, lLeftColumns).Value = strCrosstabName .Offset(, lLeftColumns + 1).Value = "Quantity" .Offset(1, 0).Resize(UBound(varOutput), UBound(varOutput, 2)) = varOutput End With Else 'Resulting flat file will fit on the sheet, so use SQL and write result directly to a pivot strMsg = " I can't turn this crosstab into a flat file, because the crosstab is so large that" strMsg = strMsg & " the resulting flat file will be too big to fit in a worksheet. " strMsg = strMsg & vbNewLine & vbNewLine strMsg = strMsg & " However, I can still turn this information directly into a PivotTable if you want." strMsg = strMsg & " Note that this might take several minutes. Do you wish to proceed?" varAnswer = MsgBox(prompt:=strMsg, Buttons:=vbOK + vbCancel + vbCritical, Title:="Crosstab too large!") If varAnswer <> 6 Then Err.Raise 999 If ActiveWorkbook.Path <> "" Then 'can only proceed if the workbook has been saved somewhere Set wksSource = rngLeftHeaders.Parent 'Build part of SQL Statement that deals with 'static' columns i.e. the ones down the left For Each cell In rngLeftHeaders 'For some reason this approach doesn't like columns with numeric headers. ' My solution in the below line is to prefix any numeric characters with ' an apostrophe to render them non-numeric, and restore them back to numeric ' after the query has run If IsNumeric(cell) Or IsDate(cell) Then cell.Value = "'" & cell.Value strLeftHeaders = strLeftHeaders & "[" & cell.Value & "], " Next cell ReDim arTemp(1 To lngMAX_UNIONS) 'currently 25 as per declaration at top of module ReDim arSQL(1 To (rngRightHeaders.Count - 1) \ lngMAX_UNIONS + 1) For i = LBound(arSQL) To UBound(arSQL) - 1 For j = LBound(arTemp) To UBound(arTemp) Set rngCurrentHeader = rngRightHeaders(1, (i - 1) * lngMAX_UNIONS + j) arTemp(j) = "SELECT " & strLeftHeaders & "[" & rngCurrentHeader.Value & "] AS Total, '" & rngCurrentHeader.Value & "' AS [" & strCrosstabName & "] FROM [" & rngCurrentHeader.Parent.Name & "$" & Replace(rngCrossTab.Address, "$", "") & "]" If IsNumeric(rngCurrentHeader) Or IsDate(rngCurrentHeader) Then rngCurrentHeader.Value = "'" & rngCurrentHeader.Value 'As per above, can't have numeric headers Next j arSQL(i) = "(" & Join$(arTemp, vbCr & "UNION ALL ") & ")" Next i ReDim arTemp(1 To rngRightHeaders.Count - (i - 1) * lngMAX_UNIONS) For j = LBound(arTemp) To UBound(arTemp) Set rngCurrentHeader = rngRightHeaders(1, (i - 1) * lngMAX_UNIONS + j) arTemp(j) = "SELECT " & strLeftHeaders & "[" & rngCurrentHeader.Value & "] AS Total, '" & rngCurrentHeader.Value & "' AS [" & strCrosstabName & "] FROM [" & rngCurrentHeader.Parent.Name & "$" & Replace(rngCrossTab.Address, "$", "") & "]" If IsNumeric(rngCurrentHeader) Or IsDate(rngCurrentHeader) Then rngCurrentHeader.Value = "'" & rngCurrentHeader.Value 'As per above, can't have numeric headers Next j arSQL(i) = "(" & Join$(arTemp, vbCr & "UNION ALL ") & ")" 'Debug.Print Join$(arSQL, vbCr & "UNION ALL" & vbCr) ''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ' When using ADO with Excel data, there is a documented bug ' causing a memory leak unless the data is in a different ' workbook from the ADO workbook. ' http://support.microsoft.com/kb/319998 ' So the work-around is to save a temp version somewhere else, ' then pull the data from the temp version, then delete the ' temp copy sTempFilePath = ActiveWorkbook.Path sTempFilePath = sTempFilePath & "\" & "TempFile_" & Format(Time(), "hhmmss") & ".xlsm" ActiveWorkbook.SaveCopyAs sTempFilePath ''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' If Application.Version >= 12 Then 'use ACE provider connection string sConnection = "Provider=Microsoft.ACE.OLEDB.12.0; Data Source=" & sTempFilePath & ";Extended Properties=""Excel 12.0;""" Else 'use JET provider connection string sConnection = "Provider=Microsoft.Jet.OLEDB.4.0; Data Source=" & sTempFilePath & ";Extended Properties=""Excel 8.0;""" End If Set objRS = CreateObject("ADODB.Recordset") Set oConn = CreateObject("ADODB.Connection") ' Open the ADO connection to our temp Excel workbook oConn.Open sConnection ' Open the recordset as a result of executing the SQL query objRS.Open Source:=Join$(arSQL, vbCr & "UNION ALL" & vbCr), ActiveConnection:=oConn, CursorType:=3 'adOpenStatic !!!NOTE!!! we have to use a numerical constant here, because as we are using late binding Excel doesn't have a clue what 'adOpenStatic' means Set objPivotCache = ActiveWorkbook.PivotCaches.Create(xlExternal) Set objPivotCache.Recordset = objRS Set objRS = Nothing Set pt = objPivotCache.CreatePivotTable(TableDestination:=rngOutput) Set objPivotCache = Nothing 'Turn any numerical headings back to numbers by effectively removing any apostrophes in front For Each cell In rngLeftHeaders If IsNumeric(cell) Or IsDate(cell) Then cell.Value = cell.Value Next cell For Each cell In rngRightHeaders If IsNumeric(cell) Or IsDate(cell) Then cell.Value = cell.Value Next cell With pt .ManualUpdate = True 'stops the pt refreshing while we make chages to it. If Application.Version >= 14 Then TabularLayout pt For Each cell In rngLeftHeaders With .PivotFields(cell.Value) .Subtotals = Array(False, False, False, False, False, False, False, False, False, False, False, False) End With Next cell With .PivotFields(strCrosstabName) .Subtotals = Array(False, False, False, False, False, False, False, False, False, False, False, False) End With With .PivotFields("Total") .Orientation = xlDataField .Function = xlSum End With .ManualUpdate = False End With Else: MsgBox "You must first save the workbook for this code to work." End If End If unpivot = Success timetaken = timetaken - Now() Debug.Print "UnPivot: " & Now() & " Time Taken: " & Format(timetaken, "HH:MM:SS") errhandler: If Err.Number <> 0 Then Select Case Err.Number Case 999: 'User pushed cancel. Case Else: MsgBox "Whoops, there was an error: Error#" & Err.Number & vbCrLf & Err.Description _ , vbCritical, "Error", Err.HelpFile, Err.HelpContext End Select End If Application.ScreenUpdating = True End Function Private Sub TabularLayout(pt As PivotTable) With pt .RepeatAllLabels xlRepeatLabels .RowAxisLayout xlTabularRow End With End Sub |
That’s a lot of code Jeff.
Assume a table of 11 rows and 10 columns.
Remove the fieldnames of the columns that have to be repeated for every record.
The remaining columns have to be read into separate records.
The last column will contais valuen (as in your example)
The one to last column of each record will contain the columnlabel (fieldname) of the values (as in your example)
Sub M_snb()sn = Cells(1).CurrentRegion
x = Cells(1).CurrentRegion.Rows(1).SpecialCells(2).Count
y = UBound(sn, 2) - x
sp = Application.Index(sn, Evaluate("index(mod(row(1:" & x * (UBound(sn) - 1) & ")-1," & UBound(sn, 2) + y & ")+" & y & ",)"), Evaluate("if(column(A1:" & Chr(66 + y) & x * (UBound(sn) - 1) & ")=" & y + 2 & ",int((row(1:" & x * (UBound(sn) - 1) & ")-1)/" & UBound(sn, 2) + y & ")+" & y + 1 & ",column(A1:" & Chr(66 + y) & x * (UBound(sn) - 1) & "))"))
For j = 1 To UBound(sp) - 1
sp(j, UBound(sp, 2) - 1) = sn(1, (j - 1) \ (UBound(sn) - 1) + y + 1)
Next
Cells(20, 1).Resize(UBound(sp), UBound(sp, 2)) = sp
End Sub
Note, this is provided without warranty….
Mine isn’t quite as elegant as snb’s but its generalized…. I don’t pull the data into an array so it does have a slight performance hit.
There’s a lot of good work going on around this subject.
Hi snb. That looks elegant. I haven’t had a chance to step through it yet, but looking forward to it.
Yeah, mine is pretty complex compared to yours. That said, I built it because I needed to handle the case where unwinding a big crosstab would result in a flat file that would exceed the row limit in Excel. I originally wrote this when my old workplace had Excel 2003, and so was coming up on that limit all the time. And more recently I had a private client that had a crosstab filled with economic data so big that it would have exceeded the row limit in new Excel if unwound the traditional way. So this code was perfect.
(Of course, they should never have got into the situation in the first place of having such a big crosstab. But they simply didn’t know any better until it got so bad that they were forced to pay me to fix it. I love organizations like that who misuse Excel, because they pay me to fix what shouldn’t have been broken in the first place).
Your code works fine for me with 11 rows times 8 columns, but if I have 10 columns then I get some REF errors. Haven’t stepped through it yet to find out why.
I’d be interested in how you would amend it so it would handle any size crosstab (within the row limit of Excel, of course). And I’d also be interested at comparing speed on very large crosstabs…particularly because I’m building a commercial add-in and want to have routines that are as fast as possible across a range of different datasets.
Thanks Patrick – I’ll check out your code over the next couple of days.
Hey Patrick: Can you give me an example of how you call this code? I seem to be doing something wrong.
This is all very useful, Jeff! I’ve used John W’s one-column flattening in the past, and also Bacon’s concatenation trick. But this seems much more powerful.
Juanito
snb: your code isn’t working so well for me.
This is the table I’m using it on:
…and this is what it is returning:
Basically this is the code you need:
Sub M_snb()sn = Cells(1).CurrentRegion
x = Cells(1).CurrentRegion.Rows(1).SpecialCells(2).Count
y = UBound(sn, 2) - x
ReDim sp(1 To x * (UBound(sn) - 1), 1 To 4)
For j = 1 To UBound(sp)
m = (j - 1) Mod (UBound(sn) - 1) + 2
n = (j - 1) \ (UBound(sn) - 1) + y + 1
sp(j, 1) = sn(m, 1)
sp(j, 2) = sn(m, 2)
sp(j, 3) = sn(1, n)
sp(j, 4) = sn(m, n)
Next
Cells(20, 1).Resize(UBound(sp), UBound(sp, 2)) = sp
End Sub
The original suggestion should be rephrased into
Sub M_snb()sn = Cells(1).CurrentRegion
x = Cells(1).CurrentRegion.Rows(1).SpecialCells(2).Count
y = UBound(sn, 2) - x
sp = Application.Index(sn, Evaluate("index(mod(row(1:" & x * (UBound(sn) - 1) & ")-1," & UBound(sn) - 1 & ")+2,)"), Evaluate("if(column(A1:" & Chr(66 + y) & x * (UBound(sn) - 1) & ")=" & y + 2 & ",int((row(1:" & x * (UBound(sn) - 1) & ")-1)/(" & UBound(sn) - 1 & "))+" & y + 1 & ",column(A1:" & Chr(66 + y) & x * (UBound(sn) - 1) & "))"))
For j = 1 To UBound(sp)
sp(j, UBound(sp, 2) - 1) = sn(1, (j - 1) \ (UBound(sn) - 1) + y + 1)
Next
Cells(20, 1).Resize(UBound(sp), UBound(sp, 2)) = sp
End Sub
Jeff – Great code – There is a limitation of 256 Columns though with this method as well as my method.
Call UnpivotRange(oWksSource.Range(“Source”), oWksTarget.Range(“A1”), True, 1, 2, 3, 4)
This would call if if you want columns 1,2,3,4 to be repeatable
The limit of 255 Columns is not there with Power Queries Unpivot – I just tried it on a data set with 305 Columns – Happened in a flash !
Juanito: snb’s code is the clear winner in terms of performance. So check out http://dailydoseofexcel.com/archives/2013/11/21/unpivot-shootout/ to get a ‘weaponized’ version of it.
snb: that’s fast. Originally I was doing it via manipulation of ranges, but of course that was too slow on large crosstabs. And at the time I didn’t have the programming chops to do the array version you posted above, so went with the multiple consolidation route instead, and then the SQL route to handle super big crosstabs for a client. But 99.99999% of the time, your code will suffice. Thanks for posting it.
@Jeff
The 65536 boundary can be tackled rather simply using:
Sub M_snb()sn = Cells(1).CurrentRegion
x = Cells(1).CurrentRegion.Rows(1).SpecialCells(2).Count
y = UBound(sn, 2) - x
For j = 1 To UBound(sn) \ 65000 + 1
ReDim sq(1 To 65000, 1 To 4)
For jj = 1 To 65000
m = (65000 * (j - 1) + jj - 1) Mod (UBound(sn) - 1) + 2
n = (65000 * (j - 1) + jj - 1) \ (UBound(sn) - 1) + y + 1
sq(jj, 1) = sn(m, 1)
sq(jj, 2) = sn(m, 2)
sq(jj, 3) = sn(1, n)
sq(jj, 4) = sn(m, n)
Next
Cells(20, 1).Offset(, j * 8).Resize(UBound(sq), UBound(sq, 2)) = sq
Next
End Sub
Hi snb. I might not have made my intent clear. My unpivot code is usually just a vehicle to get a crosstab into a pivot so that I can do easier analysis. But that 65k row limit in old excel – or 1m row limit in new excel – means you can’t always get from a crosstab to a pivot via your fast method of creating a flat file in the worksheet, because the flat file might well be too long to fit on the worksheet. Which is why I wrote the SQL approach.
So producing a flat file is a means to an ends, and not the end goal itself. Thinking about this some more, I think a much quicker way than my UNION ALL approach would be to populate a disconnected recordset, then using that to set up the pivotcache. I’ll give that a spin.
So what will you be using the resulting table for ?
I turn a crosstab into a pivot so that i can do some kind of reporting or dashboard on the aggregated data.
You can make the analyses based on the resulting array, I suppose.
So writing to the worksheet won’t even be necessary.
I find a PivotTable is perfect in the case that users want to be able to filter, aggregate, view different dimensions etc on the fly. In short, pivots give the user a way to explore the data, and see what insights they discover.
At the same time, I find Pivots perfect for fixed reports too in my reporting apps. If a user comes up and says “Hey this output is great, but it would be good if I also had another table that broke this down by Capex/Opex and by Cost Type” then I simply make a copy of the pivot, add some filters, and then say “There you go, all done”. Or I put in a ‘Custom View’ sheet where users can roll their own reports.
Your code is perfect for practically all crosstab datasets I come across, where the client wants to put it into a pivot. Occasionally I strike a client with a particulary large crosstab that requires another approach. Sometimes this is because they have bad data practices e.g. putting way too much data into Excel instead of learning how to use Access. Sometimes this is due to how 3rd party data arrives at their machines e.g. e.g. downloading some weather data over a long timespan for many sites, and the web interface spits it out as a crosstab rather than say a flat file csv. Either way, they need to get this into a pivot on their own, without anyone’s help. They have no VBA or SQL skills, and perhaps limited or slow IT support for data transformations. That’s the nut that my code tackles.
This might be an even simpler method:
Assuming a Table
– of which the first 2 columns have to be repeated
– the column label has to be adde in the 3 colum of the resulting list
– the 4th column contains the data for each column in the original Table.
Sub M_snb()With sheet1.Cells(1).CurrentRegion
sn = .Resize(, .Columns.Count + 1)
End With
For j = 3 To UBound(sn, 2) - 1
With Sheet2.Cells(2 + (UBound(sn) - 1) * (j - 3), 1)
.Resize(UBound(sn) - 1, 4) = Application.Index(sn, Evaluate("row(2:" & UBound(sn) & ")"), Array(1, 2, UBound(sn, 2), j))
.Resize(UBound(sn) - 1, 1).Offset(, 2) = sn(1, j)
End With
Next
End Sub