Quick post. I was writing up the Double-VLOOKUP trick I learnt from Charles Williams for the book.
Standard VLOOKUP on unsorted data:
=VLOOKUP([@ID],Table2,2,FALSE)
Double VLOOKUP trick on sorted data:
=IF(VLOOKUP([@ID],Table2,1,TRUE)=[@ID],VLOOKUP([@ID],Table2,2,TRUE),NA())
The point of the double VLOOKUP trick is this:
- Standard VLOOKUPS on unsorted data are slow, because your VLOOKUP has to look at each item in turn until it finds a match. So on average, it looks at – and discounts – half the things in your lookup list before it finds that match.
- Binary searches are lightning fast. Because your data is sorted, they can start half way through the lookup list, and check if the item at that point is bigger or smaller than what they’re looking for. Meaning they can ditch half the list immediately, then look halfway through the remainder. And over and over, ditching half the list each time until they either find the item they are looking for, or rule out all items.
- VLOOKUP and MATCH will quite happily do a binary search for you. But for reasons known only to Microsoft, they offer an exciting plot-twist: if they don’t find what you’re looking for in the list, they return the closest match they can find to it, which happens to be the only thing left in the list when they’d divided it in half enough times. Only they don’t tell you its not an exact match. Phooey.
- Charles’ brilliant trick is to do two lightning-fast Binary searches – the first one simply looks for the closest match to your input term among the Lookup terms. If it’s an exact match with what you fed it, you know your lookup term is in the list. So now that you KNOW it’s there for sure, you kick off a second approximate match VLOOKUP, which will grab the corresponding value you want from the lookup table. Go read his blog for the specifics.
I’ve known about this for a while, but it’s only as I’m writing this up for the book that I’ve gained an appeciation of just how much faster Binary Searches – and the Double VLOOKUP trick that gets around Microsoft’s crap implementation of them – are, compared to unsorted/linear VLOOKUPs.
See for yourself:
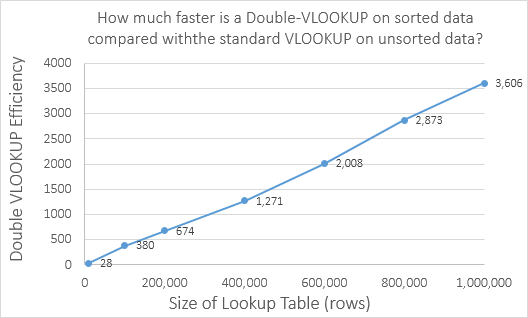
That says that:
- At one extreme, if your lookup table has 10,000 things in it, the double VLOOKUP trick on sorted data is 28 times faster than the standard VLOOKUP on unsorted data
- At the other, if your lookup table has 1,000,000 things in it, the double VLOOKUP trick on sorted data is 3,600 times faster than the standard VLOOKUP on unsorted data
Kinda puts the ‘hassle’ of sorting your lookup table ascending into perspective, don’t it!
Don’t be too harsh on the binary vlookup not telling you the match was not exact. I often use it (or match) to find the appropriate row of data in an ordered table–for example a tax table.
Also, while its often stated it finds the closest value, that is not true. In an ascending series, it finds the last number that is less than or equal to the lookup value, which may not be the closest. You and other experts know this, but I thought this post should have a correct statement of what the function finds.
Derk: True in both cases. And I’m not harsh on the binary vlookup not telling you the match was not exact. Rather I’m harsh that MS didn’t give us another option – to do an exact match binary search.
Here’s how VLOOKUP should have been implemented:
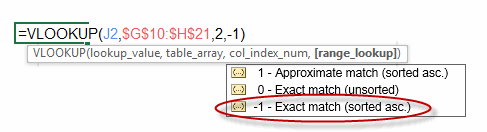
Besides, you accountant types already had the LOOKUP function, which does exactly what you need it to.
@Jeff: If you use INDEX/MATCH instead of VLOOKUP – and place the MATCH part in a different cell, you can increase it again by a factor close to 2, as you only have to do the searching part once!
Damn, that’s so obvious that I cannot believe I didn’t think of it…especially given I talk about using MATCH to cache results in the previous chapter! Thanks, Peter…you’ve saved me a major oversight in the book.
@Peter: Actually it turns out that splitting out MATCH in this particular case is actually slightly slower. It seems that the binary search is so fast that there’s actually more overhead involved in retrieving the cached MATCH result from another cell than simply redoing that lightning-fast binary search again.
Actually, i take it back: splitting out MATCH is slightly faster. But the performance increase is microscopic. For instance, for a lookup table with one million items in it, here’s the average time over 10 passes for 100 formulas (or 100 * 2 in the MATCH case, given we’ve split the MATCH bit out):
0.00114776 seconds (VLOOKUP)
0.00111296 seconds (MATCH)
In short, it certainly ain’t worth the hassle of setting up another column.
Peter & Jeff – I had a similar thought and wrote a UDF to check the times for the various options:
The results on a table with 1 million rows, with the lookup value about 3/4 of the way down were:
Exact / Binary x 1 / Binary x 2 / Match + Index x 2
0.797 0.203125 0.390625 0.8125
Note that the first result is for only 100 loops, compared with 100,000 for the others.
So I found that the binary VLookup with check was about 2000 times faster than the Exact VLookup, but also about twice as fast as the Match + Index!
I’m not sure why my Match + Index results were so much slower than Jeff’s. Maybe because it’s all in VBA and so doesn’t use multi-core processing.
Anyway, I’m going to turn this into a UDF to return the answer, rather than the time (using the double VLookup), to save myself some typing, and also so I can add an optional tolerance, rather than checking for an exact match.
Doug: maybe because the transfers between VBA and Excel?
My code is based on the routine from joeu2004 at http://www.mrexcel.com/forum/excel-questions/762910-speed-performance-measure-visual-basic-applications-function.html
This thread is worth a read, because it makes this important point: we cannot measure the performance of “a” formula simply by measuring one instance of the formula. (But that does depend on the nature of the formula and the situation that we are trying to measure. Sometimes we need to measure one instance of a formula, but increase the size of ranges that it references in order to overcome the effects of overhead.)
I’ll post my TimeFormula routine in the near future…I’m just making some additional tweaks.
I performed my experiments by putting =randbetween(1,1000000) in cells A2:A100000 then turning it to values, then sorting it a to z. Then for the lookup values I put =randbetween(1,1000000) in 100 cells, again turned them to values, then did the lookups. This gave me a good random spread and lots of no matches (about 40%).
Thanks for the link Jeff, very interesting.
Using a modified version of the joeu200 routine, with the lookup functions in 50 rows, my match/index function really speeds up, and is 50-80% faster than the binary VLookup with check.
My procedure was much the same as yours, except I initially selected my lookup values so that they all had matches, and then I modified half of them so there was no match.
The ratio for (Match-Index)/(Exact VLookup) was about 6800 when all the lookup values had an exact match, and 10700 when half of the values did not have any match. That makes sense, because if there is no match the exact VLookup has to check the entire list.
My UDF times were of the same order of magnitude per lookup as the subroutine took for 50 lookups, so it looks like most of the time for the UDF was data transfer.
‘we cannot measure the performance of “a” formula simply by measuring one instance of the formula’
Very true. From tests on several hundred thousand rows, the cell formulas themselves only appear to take around a microsecond to calculate and that still doesn’t change much with INDEX/MATCH v double LOOKUP specifications. These results tend to agree with Jeff’s initial take that you’re losing out from splitting calculations into separate cells with well optimised functions like these but you won’t really notice unless you have such large lookup tables to fill.
One other point is that when there are multiple values equal to the lookup value, the lookup formula seems to go through the list in a linear (not binary) fashion. So if column A consists entirely of 1’s, filling down =LOOKUP(1,A:A) takes a lot longer than =LOOKUP(2,A:A).
I have just discovered why my Match/Index combination sped up so match. To find the recalc time per row I divided the total time by the number of cells in the recalc range, rather than the number of rows, so the Match/Index result was divided by 100, and everything else was divided by 50.
When I correct for that the double VLookup is faster than Match/Index.
I have also modified my UDF to work as an array function which improves its performance substantially. Returning 50 rows it took 2.9 times longer, and for 100 rows this came down to 1.7 times, compared with the double VLookup on the spreadsheet.
Yeah, that will do it. In the timing code I present in the next post on this, I show both the average time to calculate the selected entire range over 10 passes, and the average time per cell over those 10 passes. So in the case where I’m comparing a mega formula to a formula split across multiple columns, I can still make a valid comparison.
Splitting the MATCH is faster than the MATCH/INDEX combo – But the speed difference is significant only when you have multiple columns to Pick
So a Single Match Column and 10 Index Columns referring to the MATCH column will be significantly faster than 10 MATCH/INDEX combos
My test on 10 columns of 100 lookups each on 1 million rows shows that splitting MATCH out resulted in a time of 0.004983096 as opposed to the double VLOOKUP approach of 0.007192451.
Not a lot in it…
Further to Sam’s comment, intuitively one would think it’s faster to split repeated calculations within a formula into separate cells. But using a setup similar to the one Jeff described above and filling these formulas over a large range:
=IF(LOOKUP(B2,A:A)=B2,LOOKUP(B2,B:B),NA())
=IF(INDEX(A:A,MATCH(B1,A:A))=B1,INDEX(B:B,MATCH(B1,A:A)),NA())
the results show that both take close to 1 microsecond to calculate (roughly in line with joeu2004’s 0.9 microseconds for RAND). Splitting the match part out into another cell actually takes twice as long – a little over 2 microseconds.
Presumably there’s overhead both in calculating an extra cell and in adding a layer to the dependency tree. So using a helper column only pays off if you have a sufficient number of repetitions of the formula to calculate.
Wow, interesting! Wouldn’t have expected that split out the MATCH would gain so little…
@Jeff: Regarding the “not worth the hazzle setting up another column”: Having said that, I still think it’s best practice in most situations, as splitting larger formulas across multiple cells also eases the understanding/lowers the risk of a bug! So if I need to look up more than one column of the same row, I usually 2 support columns:
Row: =MATCH([@Id],SourceTable[IdColumn])
Check: =INDEX(SourceTable[IdCol9,[@Row])=[@Id]
LookUpX: =IF([@Check],INDEX(SourceTable[LookupColumnX],[@Row]),FallbackFunction)
Makes each formula easy to understand and less error-prone! Esp. the hardcoded column index in the VLOOKUP is a big no-go to me. Of course, I could replace this with another MATCH and then place this part in another cell for performance reasons – but then why not use INDEX/MATCH from the start?!? :-)
Good point, Peter, and in fact I decided to make that point in the book.
You also need to consider multi-threading: splitting formulas into separate cells increases the chances of calculating formulas in parallel. Note that Range.Calculate and VBA UDFs always calculate single-threaded.
Thanks Charles. A quick google search seems to show that there’s not much in the way of plain-English explanations on multithreading out there. Or if there is, it’s buried way down the list. One exception is the content at your site http://www.decisionmodels.com/calcsecretsc.htm#MultiThread and again at https://msdn.microsoft.com/en-us/library/office/ff700514%28v=office.14%29.aspx#MultithreadedCalculation
I also see there was a good blog post from Diego Oppenheimer–a former program manager for Microsoft Excel-back in 2005 at http://blogs.office.com/2005/11/03/multi-threaded-calculation-in-excel-or-how-calculation-can-become-much-faster-in-excel-12/ for anyone following along at home.
This is amazing! Thanks Jeff.
I’m grasping at straws trying to speed up my macro which uses FIND. I have a 200,000 record file of all the properties in a particular City or Town. Each parcel takes up about 10 rows and 10 columns of data. There is a Street Address and/or a Tax id code which is unique. I’m using find a few times to ensure I have the proper property. If, for example, I am looking for 12.2-3.32 I might find 112.2-3.32 or 12.2-3.322. So I loop through the file with multiple FINDS until I get the right one. Any other options for me to speed up the macro other than FIND? I can’t use VBLOOKUP since the file is NOT sorted. Thanks.