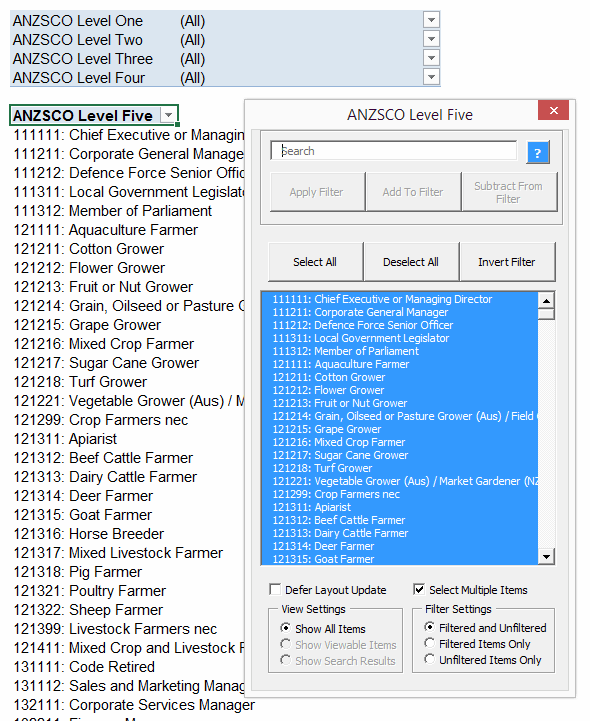
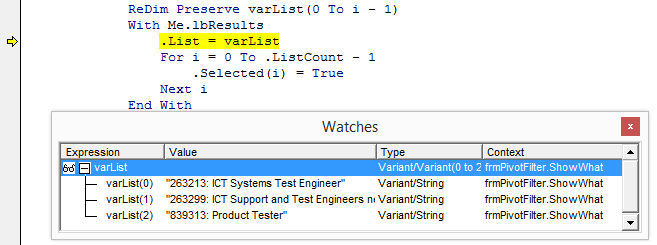
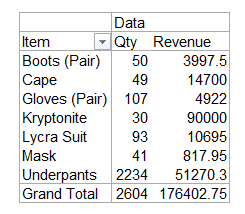
I’m in the final stages of coding up a commercial add-in that gives you lot more filtering options for PivotTables at your fingertips than you get out of the box. Here’s how it looks, along with the PivotTable its connected to and a native Slicer for comparison:
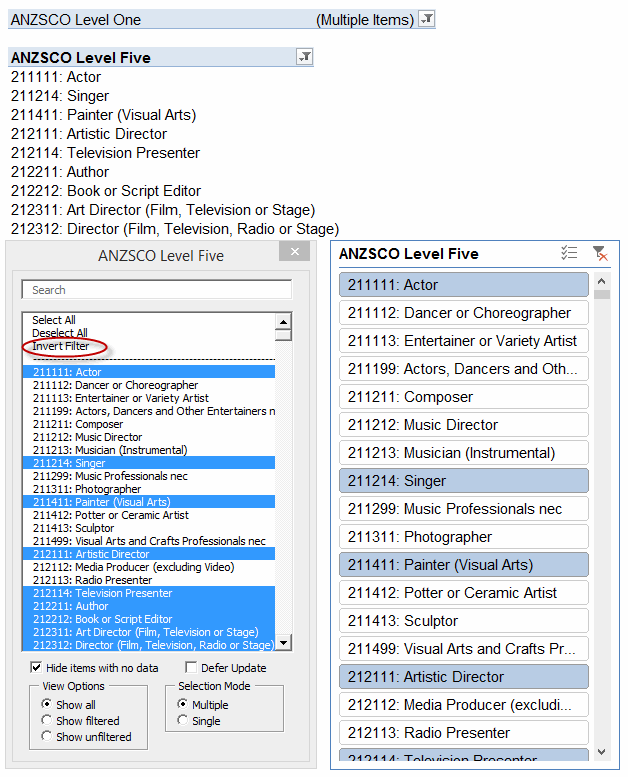
As you can see, it offers you a lot more tricks than a native Slicer – including a nifty ‘Invert Filter’ function. It also lets you see a lot more items displayed in it compared to a Slicer: 22 items are visible in mine, vs just 17 in the correspondingly sized Slicer. And that’s one of the many beefs I have with Slicers…they take up far too much screen real estate for the scant options they offer. In fact, my version takes up no screen real-estate most of the time: it launches simply by double-clicking the PivotTable field header, and you can dismiss it when you’re done to free up space if you want:
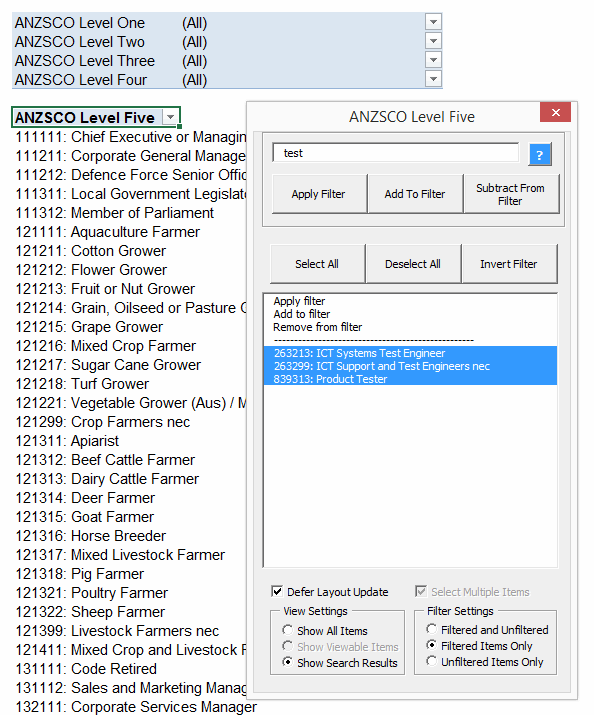
So about that Invert Filter function. I love clicking on that sucker over and over again. It takes about 7 seconds to invert my sample PivotTable that has 1000 items in it (12 items of which are selected in this example). That’s actually pretty fast as far as inverting a PivotTable, because you need to change the .visible status of all 1000 PivotItems, and as per a previous post that’s very slow to do unless you get tricky. And 7 seconds is a vast improvement on the method Microsoft gave you…none. I can’t comprehend why simple options like these are not built in to Slicers and Tables, but your filtering pain is (hopefully) my financial gain. (Yep, this works on Tables too.)
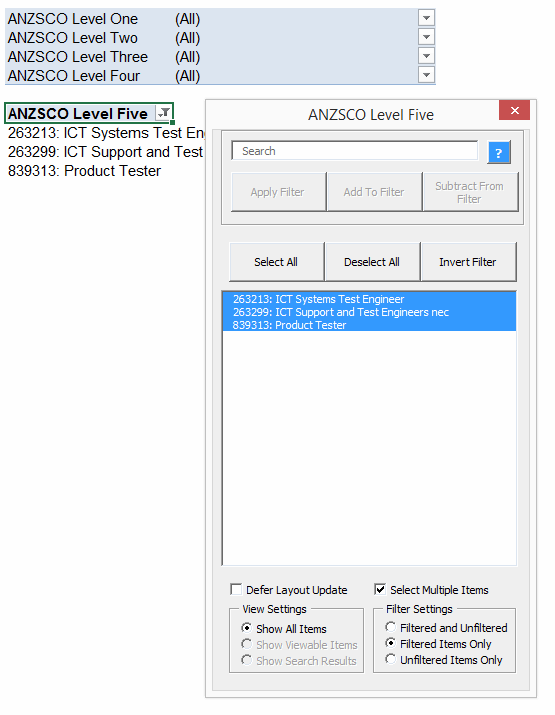
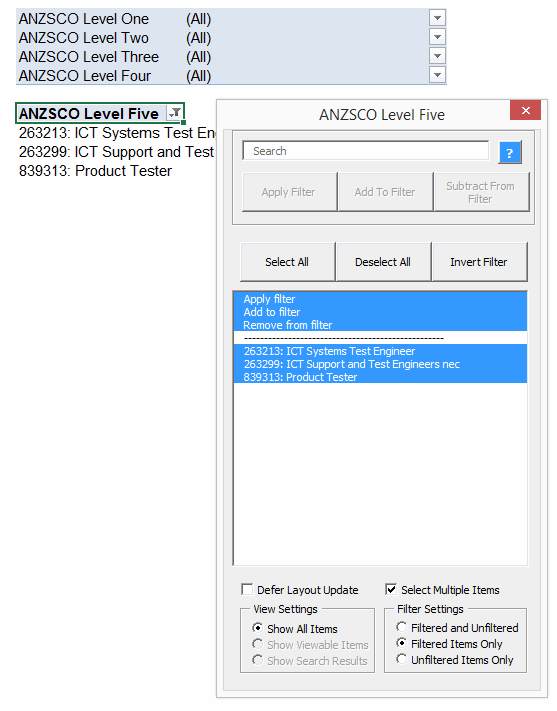
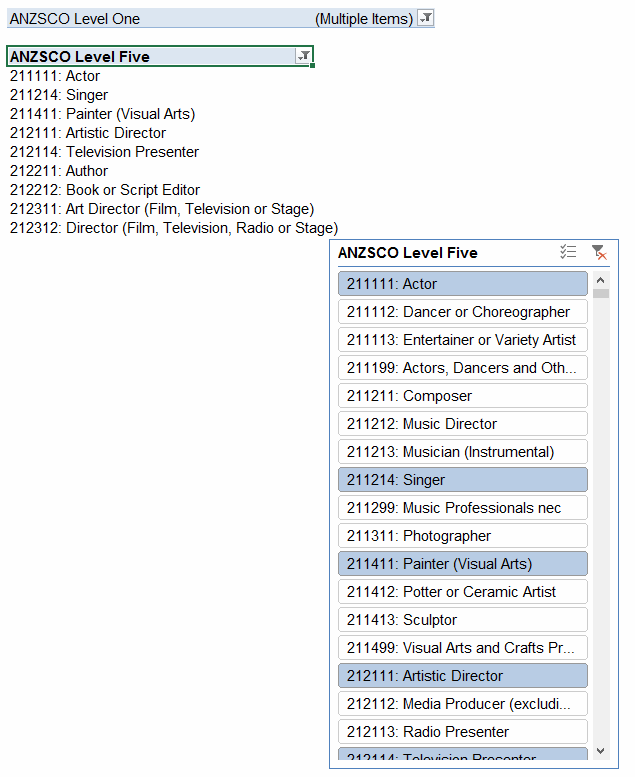
If I click that Invert Filter label, then here’s the after-effect:
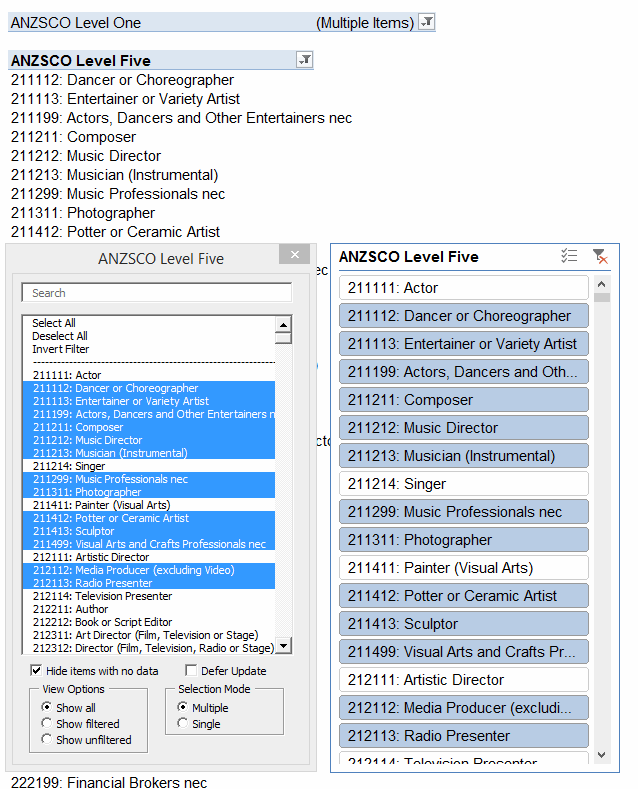
Beautiful: 7 seconds, and she’s turned completely inside out. Unless that is, that Slicer happens to be selected. Then it takes a full minute. Why? No idea. Moral of the story: if you’re writing code to filter PivotTables, then you probably want to make sure any Slicers for that field are deselected first. Not disconnected…you can leave ’em in place quite happily, and the code won’t suffer.
Anyways, that’s the first look at my new baby. It does a lot more than just this inverting trick, too. Among other tricks, it lets you filter PivotTables based on external ranges, and gives you some absolutely fantastic new tools for filtering PivotFields based on just about any tricky search conditions you might want to string together – but that’s a subject for my next post.