Howdy folks. Jeff Weir here, hacking into Dick’s blog. Quickest bit of hacking I ever did, too: while Dick had prudently used an alpha-numeric password, it didn’t take me very long to hit upon his super-obfuscated ILoveExcel2013. My quickest dictionary attack yet.
Speaking of Dictionaries, I thought I’d make a couple of quick comments in response to Dick’s last post The Encyclopedia of Dictionaries. Did I say quick? That’s a calumniation, if not downright obloquy.
Ah, Dictionaries. While you’re rushing for yours in order to see if I just swore at you, let me reminisce for a moment. Oh magical dictionary of my youth: how I loved to fritter the hours away thumbing through your creased pages armed with a pencil and a penchant for rude words.
Annnnyway…in Dick’s previous post, he linked to this extensive page written by snb on Dictionaries. That’s a good resource. So is this excellent article by mattheswpatrick at Experts-Exchange: Using the Dictionary Class in VBA.
One of the code snippets on snb’s page concerns de-duping records, and goes something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Option Explicit Sub Original() Dim dic As Object Dim sn As Variant Dim j As Long Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents sn = Range("A1").CurrentRegion Set dic = CreateObject("scripting.dictionary") With dic For j = 1 To UBound(sn) .Item(sn(j, 1)) = Application.Index(sn, j, 0) Next Range("D1").Resize(.count, 2) = Application.Index(.items, 0, 0) End With timetaken = Now() - timetaken Debug.Print "Original took " & Format(timetaken, "HH:MM:SS") End Sub |
(I added the Option Explicit bit in remembrance of my first well-thumbed dictionary. It certainly wasn’t. Explicit, I mean. Although at the time I thought it was. Why, even in the low B’s I came across words like “Boob.” Pretty slim pickings from W onwards, though. In hindsight I believe that putting rude words into dictionaries was a cunning ploy by teachers to get kids to learn English. Kids these days have it a lot better than I did, because today’s dictionaries have lots more rude words in them. Which probably explains why every 2nd word uttered by modern kids rhymes with the common name for a bird from the Anatidae family.)
Where was I? Ahh, that’s right. There’s a problem with the above code, in that you cannot pass an array bigger than 65536 rows to a Worksheet Function from VBA without getting a Mismatch error. That’s covered in this recent post. So point this code at a range containing 65537 rows, and you’ll get an error on the Application.Index(.items, 0, 0) bit.
In fact, point this code at 65536 rows exactly, and while it will work, it won’t work fast. That’s because it’s really expensive to call a worksheet function like Application.Index from VBA lots and lots. To the point that you don’t want to hold your insufflation while you wait: this took 16 minutes and 15 seconds on my pretty fast laptop.
We can of course rewrite this code so that it doesn’t use Application.Match, which radically speeds things up. But this still leaves you to a potentially mortiferous flaw that might bite you in a place that renders you most undecidedly callipygian. More on this postliminary. First, the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Sub Revision1() Dim dic As Object Dim varInput As Variant Dim i As Long Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents varInput = Range("A1").CurrentRegion Set dic = CreateObject("scripting.dictionary") On Error Resume Next 'Needed, because the .Add method throws an error if you try to add a key that already exists. With dic For i = 1 To UBound(varInput) .Add varInput(i, 1), varInput(i, 2) Next Range("D1").Resize(.count) = Application.Transpose(dic.keys) Range("E1").Resize(.count) = Application.Transpose(dic.items) End With On Error GoTo 0 timetaken = Now() - timetaken Debug.Print "Revision1 took " & Format(timetaken, "HH:MM:SS") End Sub |
Well, that’s slightly faster to be sure. 1 second. Even I can hold my eupnea that long.
One thing to note from the above is that the .add method I’m using throws an error if you try to add a key that already exists. Whereas the .Item method in the original code doesn’t. That error can come in handy, as we’ll see soon.
But while that approach avoids that pesky Application.Index bit, we’ve still got a potentially pernicious problem: in order to transfer the Dictionary from VBA to Excel, we’ve got to first Transpose the array to a Column Vector. And we use Application.Transpose to do that. Which begs the question: What if we end up with more than 65536 non-duplicate values in the dictionary? How will Application.Transpose handle that?
Badly.
I was thinking that the following approach would prove the fastest way around this issue:
- Keep adding things to the dictionary until it contains exactly 65536 items (or until we’ve checked everything…whichever occurs first).
- At that point, transfer those 65536 items in one go directly from the Dictionary to the worksheet.
- After that point, keep trying to add items to the dictionary. If the dictionary accepts them without complaining (which means they are not duplicates) then add them to a variant array as well.
- Transfer that variant array containing our ‘remainder’ items to the worksheet all in one hit.
Something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
Sub Revision2() Dim dic As Object Dim varInput As Variant Dim varOutput(1 To 983040, 1 To 2) As Variant Dim i As Long Dim lCount As Long Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents lCount = 1 varInput = Range("A1").CurrentRegion Set dic = CreateObject("scripting.dictionary") With dic For i = 1 To UBound(varInput) If Not dic.exists(varInput(i, 1)) Then .Add varInput(i, 1), varInput(i, 2) If i = 65536 Then 'This is the most we can transfer from the Dictionary in one go Range("D1").Resize(65536) = Application.Transpose(dic.keys) Range("E1").Resize(65536) = Application.Transpose(dic.items) lCount = 1 End If If i > 65536 Then 'Transfer remaining duplicates to VarOutut, 'so we can dump them to the worksheet in one go varOutput(lCount, 1) = varInput(i, 1) varOutput(lCount, 2) = varInput(i, 2) lCount = lCount + 1 End If End If Next If .count < 65537 Then 'we haven't yet transferred anything from the Dictionary to the worksheet Range("D1").Resize(.count) = Application.Transpose(dic.keys) Range("E1").Resize(.count) = Application.Transpose(dic.items) Else Range("D1").Offset(65536).Resize(lCount-1, 2) = varOutput If lCount > 1 And lCount < 65536 Then Range("D1").Offset(.count + 1).Resize(65536 - lCount).ClearContents End If End With timetaken = Now() - timetaken Debug.Print "Revision2 took " & Format(timetaken, "HH:MM:SS") End Sub |
So why did I Dim varOutput as (1 To 983040, 1 To 2)? Because 983040 is the difference between the number of rows in ‘new’ Excel, less the block we already transferred across before our Dictionary got too big for Application.Transpose to handle. (Edit: It makes more sense to instead ReDim this varOutput(1 To UBound(varInput, 1), 1 To 2) as Jan Karel suggests in the comments, so that is is only as big as our initial list)
I know…it seems a waste to transfer such a large block, when there might very well only be a few things in it. But that’s the way it has to be, I think. We can’t redim the array back to the actual size of the block we need to transfer, because you can only redim the last dimension of an array. And we can’t swap the order of the dimensions around in order to circumvent this, because then we’d need to use Application.Transpose after I redimmed it, in order to turn it back into a nice, downward-pointing table. So we’d be rubbing against that 65536 limit again. Which – to coin a few words from my Dictionary – is vapid and soporific. Not to mention dreich.
Despite the double handling past 65536 items, this seems pretty fast: I put the numbers 1 through 65536 in column A, and the text A1 through to A65536 in column B, and it deduped them in around 1 second flat. (Of course, this being an extreme example, it didn’t actually find any duplicates to drop. But not for want of trying). And to process 1048576 unique records took 42 seconds.
Now here’s something interesting I also discovered: when I randomly sorted that list, it took 1 minute ten seconds to process those 1048576 records. So spend a couple of seconds sorting large data ranges before you dedupe.
Hmmm…maybe that approach of transferring the first 65536 items from the dictionary – and the rest via a variant array – is overkill. What if we don’t transfer anything from the dictionary to the worksheet, but simply use the dictionary as a means to identify non-duplicates? We can then write ALL those non-duplicates to a variant array one by one as we identify them. Then we can just bring the one block of data across. Like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
Sub Revision3() Dim dic As Object Dim varInput As Variant Dim varOutput(1 To 1048576, 1 To 2) As Variant Dim i As Long Dim count As Long Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents count = 1 varInput = Range("A1").CurrentRegion Set dic = CreateObject("scripting.dictionary") With dic For i = 1 To UBound(varInput) If Not dic.exists(varInput(i, 1)) Then .Add varInput(i, 1), varInput(i, 2) varOutput(.count, 1) = varInput(i, 1) varOutput(.count, 2) = varInput(i, 2) End If Next Range("D1").Resize(.count, 2) = varOutput End With timetaken = Now() - timetaken Debug.Print "Revision3 took " & Format(timetaken, "HH:MM:SS") End Sub |
Well, it’s only slightly slower for a sorted dataset of 1048576 items and a heck of a lot simpler: 43 seconds as opposed to 42 under the much more complicated previous approach. It takes 1 minute 10 seconds if the data isn’t sorted first. If time is money, we ain’t gonna get rich off of the back of the extra complexity of the Revision2 approach vs the Revision3 approach.
Of course, another option is a bit of SQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Sub sql() Dim con As Object Dim rstData As Object Dim sDatabaseRangeAddress As String Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents Set con = CreateObject("ADODB.Connection") Set rstData = CreateObject("ADODB.Recordset") con.Open "Provider=Microsoft.ACE.OLEDB.12.0;Data Source=" & ActiveWorkbook.FullName & ";Extended Properties = ""Excel 12.0 Macro;HDR=no"";" rstData.Open "SELECT DISTINCT F1, F2 FROM [Sheet1$] ", con Range("D1").CopyFromRecordset rstData rstData.Close Set rstData = Nothing Set con = Nothing timetaken = Now() - timetaken Debug.Print "SQL took " & Format(timetaken, "HH:MM:SS") End Sub |
This took 2 min 58 seconds to process 1048576 unique numbers. Man, that’s slow. I thought it might have been because of the use of DISTINCT, so I took the DISTINCT bit out and re-ran it. It still took a long time – I think 2 min 10 seconds or something like that, but I forgot to write it down.
What about Excel’s native Remove Duplicates functionality?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Sub Excel_RemoveDuplicates() Dim rngSource As Range Dim rngDest As Range Dim timetaken As Date timetaken = Now() Range("D1:E1").EntireColumn.ClearContents Set rngSource = Range("A1").CurrentRegion Set rngDest = Range("D1").Resize(rngSource.Rows.count, 2) rngDest.Value = rngSource.Value rngDest.RemoveDuplicates Columns:=2, Header:=xlNo timetaken = Now() - timetaken Debug.Print "Remove Duplicates took " & Format(timetaken, "HH:MM:SS") End Sub |
Faster? Well, it depends. Pretty much instantaneous if your items are sorted. But it took 2min 48 seconds to run for completely randomized data. Which is pretty concerning, given it only takes a few seconds to sort data.
So there you go. Dictionaries are great, but perhaps check first how much data you have going in to them, and how much going out. Otherwise you’ll possibly get an error.
Right, that’s me. I’m off to try a pocket dictionary attack on another couple of Excel blogs. Surely at least one of them will have either ILoveBacon, ILoveBanjos, ILoveBach, ILoveCharts, or ILoveCanada as their WordPress password. Maybe even IloveDictionaries.
—Update 25/10/2013—
Prompted by some of the great comments below, I did some testing on a simple one-column dataset under a range of conditions:
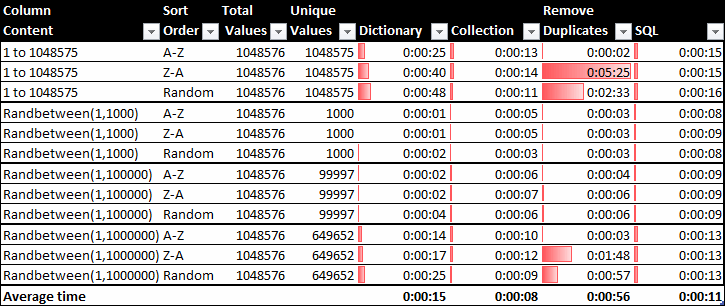
Key points:
- Remove Duplicates is very fast on datasets with lots of unique values if they are sorted
- Remove Duplicates is very slow on datasets with lots of unique values if they are not sorted
- Dictionaries are fastest on datasets sorted A to Z, slower on datasets sorted Z to A, and slowest on unsorted datasets. That’s my surname with a ‘d’ on the end. Weird.
- The Advanced Filter is not shown, because it simply can’t handle big arrays with numerous non-duplicates quickly.
Excellent article.
In my quest to program “everything VBA” I got curious: what if we do use a collection in this particular case?
So I cooked up:
And executed both your revision3 and mine:
Revision3 took 00:01:05
RevisionJKP took 00:00:28
I guess doing it all in native VBA can have its advantage.
Note I used redim to at least make that array no larger than the original range.
Hi Jan Karel. That speed difference is staggering.
I made some slight modifications to your code:
On my system, this takes 0:00:16.
Then I changed Revision3 to early binding, and used the same structure:
This executed in 0:00:51
I’m going to have to go back and reread matthewspatrick’s article, because I was under the illusion that the Dictionary would be faster.
I think you might have overlooked the essence of the cited code:
It enters an [u]array[/u] into the dictionary item, not a value.
Suppose the currentregion consists of 100 rows and 8 columns, your revision won’t handle that.
I don’t think you can compare handling arrays in dictionary itmes to handling values in dictionary items.
@snb: I know Dictionaries can do a lot more. I just want to make one point:
Don’t try to use Dictionaries (replace Dictionaries with whatever technology you like here) just because you *think* they provide the best method to solve the problem. Carefully decide (and test) whether they are *really* the best solution for the problem at hand.
So if efficiency counts, test your code for efficiency (speed, mem usage, programming ease, …) and also test alternatives. Then decide which route to take.
@Jeff: Well, as you can see the old saying applies: the proof of the pudding is in the eating.
Hi snb. I’ll have to digest that in the morning…late here and just about to go to bed. I absolutely might have missed the point, and this is complex stuff for me to get my head around :-)
Part of the reason for writing this post (which I did in a day) was to gain a better understanding of these things. And also to highlight that while it’s pretty easy to get data into a dictionary from the grid, getting it back out again into the grid requires thinking about how you are going to work around the 65536 hard-limit of the VBA/Worksheet interface. Because as I’ve pointed out, you can’t directly transfer the Dictionary keys or items back to the worksheet in one go if they have more than that amount of items in them.
And along the way, it was also very interesting to test some other approaches.
Jan Karel: I think the speed difference between your revision and mine is due to something wrong in my coding. I did some further testing with these simplified versions that just look at one column:
Sub Coln()
Dim cCol As Collection
Dim varInput As Variant
Dim varOutput() As Variant
Dim i As Long
Dim timetaken As Date
timetaken = Now()
Range(“D1”).EntireColumn.ClearContents
varInput = Range(“A1”).CurrentRegion
ReDim varOutput(1 To UBound(varInput), 1 To 1)
Set cCol = New Collection
On Error Resume Next
With cCol
For i = 1 To UBound(varInput)
Err.Clear
.Add varInput(i, 1), varInput(i, 1) & “”
If Err.Number = 0 Then
varOutput(.count, 1) = varInput(i, 1)
End If
Next
Range(“D1”).Resize(.count) = varOutput
End With
timetaken = Now() – timetaken
Debug.Print “Coln ” & Time() & ” took ” & Format(timetaken, “HH:MM:SS”)
End Sub
Sub Dic()
Dim Dic As Scripting.Dictionary
Dim varInput As Variant
Dim varOutput() As Variant
Dim i As Long
Dim timetaken As Date
timetaken = Now()
Range(“E1”).EntireColumn.ClearContents
varInput = Range(“A1”).CurrentRegion
ReDim varOutput(1 To UBound(varInput, 1), 1 To 1)
Set Dic = New Scripting.Dictionary
On Error Resume Next
With Dic
For i = 1 To UBound(varInput)
Err.Clear
.Add varInput(i, 1), varInput(i, 1)
If Err.Number = 0 Then
varOutput(.count, 1) = varInput(i, 1)
End If
Next
Range(“E1”).Resize(.count, 1) = varOutput
End With
timetaken = Now() – timetaken
Debug.Print “Dic ” & Time() & ” took ” & Format(timetaken, “HH:MM:SS”)
End Sub
Here’s my results:
Basically the Dictionary is faster if you have fewer unique values/more duplicates, and the Collection is faster if you have more unique values/fewer duplicates.
I’ll have to do some testing of the other methods too across a variety of sample data. All in good time.
Jeff, once again a literary tour-de-farce. I beg, however, to differ with your conclusions regarding RemoveDuplicates, which I maintain warrants longer shrift.
In a recent post, at http://yoursumbuddy.com/get-unique-per-row-values-removeduplicates/, I came up with code that can come up with unique values for non-contiguous columns using RemoveDuplicates. I just ran it on three columns and 1,048,576 rows of unsorted data, getting 5 unique values from the combination of columns A and C in just over two seconds.
As mentioned, it all depends on what we’re trying to do.
About the 65536 row limit – If we are using XL for over even a few thousand rows odds are we are using XL as a database. Even free databases can handle this problem in fractions of a second and can go well beyond XL’s current 1,048,576 limit. So for me, I choose not to spend time figuring out how to work around that limitation.
While ignoring limits (even though ALL of these methods work with XL’s current 1,048,576 limit), let’s discuss which XL solution makes sense for which situation. For me, they are:
[1] Removing Duplicates from a range – Use RemoveDuplicates. It’s crazy fast, is a 1 liner, handles ranges with multiple columns, and has some nice options to pick and choose key columns:
Range("D1").CurrentRegion.RemoveDuplicates Columns:=Array(1, 2), Header:=xlNo[2] Creating a list of unique values in a new range
[2a] We could Use Advanced Filter:
Range("A1").CurrentRegion.AdvancedFilter Action:=xlFilterCopy, CopyToRange:=Range("D1"), Unique:=True[2b] Oddly enough, copying the range with duplicates and then use RemoveDuplicates works even faster:
Range("A1").CurrentRegion.Copy Sheet2.Range("D1")Range("D1").CurrentRegion.RemoveDuplicates Columns:=Array(1, 2), Header:=xlNo
[3] Creating a list of Unique values from a range with the range’s contents into an Array – If our target is NOT a range, then Collections and Dictionaries make sense. This is my go to method:
Sub DicRow()Dim Dic As Object
Dim Row As Range
Dim timetaken As Date
timetaken = Now()
Set Dic = CreateObject("Scripting.Dictionary")
For Each Row In [A1].CurrentRegion.Rows
Dic(Row.Cells(1)) = Row
Next
timetaken = Now() - timetaken
Debug.Print "DicRow " & Time() & " took " & Format(timetaken, "HH:MM:SS")
End Sub
Remember that Dic.Items() and Dic.Keys() are ARRAYS! We don’t need another variable. To see a unique value, use the Dic.Keys() array like this:
Debug.Print Dic.Keys()(0)The above gets the first key. And in this example, DicItems() has the actual row range tucked into it. So to see any of the associated cells use something like this:
Debug.Print Dic.Items()(0)(1,2)The above gets the first unique row’s second cell.
Craig: While I was fixing the code tags, I fixed the zero-bound thing too. I also changed
Dic.Keys()(0)to
Dic.Keys(0)They both work the same, it seems, so I'm wondering if there's a difference. And if not, why would you choose the former over the later?
Two comments about collections. Different than dictionaries, collections can be sorted. Dick showed us how way back here:
http://dailydoseofexcel.com/archives/2004/06/02/sort-a-collection/
And different than dictionaries, collections do not have a .exists property. You have to roll your own, trapping the error. Here is the one I use.
Public Function IsIn(Col As Collection, Key As String) As Boolean
Dim errNum As Long, TEMP As Variant
errNum = 0
Err.Clear
On Error Resume Next
TEMP = Col.Item(Key)
errNum = CLng(Err.Number)
On Error GoTo 0
If errNum = 5 Then 'IsIn = False
Exit Function
End If
IsIn = True 'errNums 0 , 438
End Function
… mrt
Hiya Craig. I was hoping you’d show up. I love to argue with IT :-)
Even free databases can handle this problem in fractions of a second and can go well beyond XL’s current 1,048,576 limit. Free database aren’t. They don’t come with free IT support, or freedom from IT to implement them, unless you are IT.
You’re the IT director where you work, Craig. So you have no constraints to implementing the above. Whereas I’m currently doing some work for a large (by New Zealand standards) government department. They won’t even let us load up the free PowerPivot Addin that’s built by Microsoft for Microsoft Excel. So adding say another MYSQL implementation that is going to require their resource and be out of their control is out of the question.
Use RemoveDuplicates. It’s crazy fast. Try this:
I’ll see you back here in 5 minutes or so. This is one lousy algorithm if your data is not sorted.
Plus, it doesn’t help out in this case: http://forum.chandoo.org/threads/find-duplicate-values-in-1-8m-data.12473/ where a user has 1.8M records that they want to dedup. Yes, those records probably live in a database, so the op could probably get IT to rewrite the query that extracted those records so that they come through as distinct in the first place. But IT can sometimes be damn unresponsive. I used to email such basic requests to an IT guy in a small firm, and I’d never hear back, because his time management skills sucked. I had to email the request, then go see him on another floor and insist he did it while I was there. Give me ‘inefficient’ Excel any day, because I’m the only one in the driver’s seat.
Remember that Dic.Items() and Dic.Keys() are ARRAYS! We don’t need another variable. Your sample code puts some data into a dictionary. It doesn’t spit it back out again. What if that dictionary contains over 65536 items? How do you get it back into the worksheet? That’s why I’m using another variable.
[2a] We could Use Advanced Filter. Yeah, I forgot to mention this in my post. Put =randbetween(1,100,000) in column A, and convert to values. Now run the advanced filter on that, and select the ‘Unique Records Only’ option. I’ll see you back here after you’ve restarted Excel.
Hey, thanks for the comments. Always fun reminding IT that not all users are IT :-)
@Doug. Ha! Literary tour-de-farce…that’s a good one. Hey, your post is brilliant. I missed it somehow. (Sometimes I tend to skim over long posts, although I have no qualms about writing an even longer one!).
Check out my comments above re Excel’s Remove Duplicates. Sort your data first, is my advice. And bad luck if you want to dedup more than 1,048,576 records.
@Jeff
The code you cited was meant for this situation:
Sub M_delete_duplicates()sn = Sheets("Sheet1").Cells(1).CurrentRegion.Resize(, 5)
With CreateObject("scripting.dictionary")
For j = 1 To UBound(sn)
.Item(sn(j, 1)) = Application.Index(sn, j, 0)
Next
sp = Application.Index(.items, 0, 0)
MsgBox UBound(sn) & vbTab & UBound(sp, 2)
Sheets("Sheet1").Cells(1, 10).Resize(.Count, UBound(sn, 2)) = Application.Index(.items, 0, 0)
End With
End Sub
It also illustrates that you can construct a 2-dimensional array based on a 1-dimensional array .items, using:
sp = Application.Index(.items, 0, 0)@Jeff, thanks! Again, though, my point is that the code in that post is really fast without sorting. I wonder if the difference is because my code does the operation in a brand-new temporary workbook.
Doug: “Really Fast” depends on how many records, and with some approaches speed decreases non-lineally in relation to an increase in records. So we can never assume that an approach that is fastest with a dataset of rows x will also be fastest with a dataset of 2x or (heavens forbid) x^2. Check out the table I’ve added at the bottom of my original post above to see what I mean.
@snb. I see your intent now. If you feed an entire table row by row to the dictionary using the .item property, then the dictionary automatically uses the first item in that array as the key, and stores the entire line as the item.
So as written, your code looks for the last occurring duplicate items in row A of the table, and returns the whole row. So if we feed it this:
…it will return these rows:
That’s cool. I knew you could assign other objects (e.g. arrays, dictionaries) to a dictionary, but I didn’t know that if you did this via the .item property it would automatically assign the first element in the array as a key. Sweet.
That said, the poor speed performance of Application.Index(sn, j, 0) within the loop limits the practicality of this approach severely. To the point that you would want to seriously reconsider using this approach if there was any chance that you would have more than a few thousand rows.
For instance, here’s what I get if I fill 5 columns with =RANDBETWEEN(1,100)
1000 rows: 1 second
5000 rows: 13 seconds
10000 rows: 54 seconds
15000 rows: 2 minutes
65536 rows: 16 minutes
Anything greater: Code fails
It would actually be much faster to concatenate all the columns together in the worksheet, attempt to add the key to the dictionary along with the concatenated records, and then spit the deduped records back to the worksheet, and then split them back into separate columns.
Or if you don’t want to do the concatenation in the worksheet, you can do it in VBA like this:
That takes 1 second to do 65536 records.
@Jeff
Re. RemoveDuplicates
Dost thou thinketh I dare break the first IT commandment – “THOU SHALT TEST!”
Code:
Sheet2.Range(“A1”).CurrentRegion.RemoveDuplicates Columns:=Array(1, 2), Header:=xlNo
Data:
Unsorted. 3 Columns in data. Used 2 Columns for unique items. Used random A## format (Random Alpha & Random 2 digit number). 1,048,567 rows.
Results:
3 seconds
And yes – it takes less than a second for a mere 65,536 rows.
Re. Free Databases – Damn IT.
We don’t need MS Access to put data in MS Access tables. SQL Server Express can be loaded onto a PC and run by mere mortals. No DBA daemons required. And yse – it’s good to by King. As ruler I shall not lead my people unto darkness but rather into the light of best practices. So don’t expect me to support using XL as a database. It ain’t. It’s a good thing that poor slob working with 1.8 million records in XL has people like you – cause my ONLY advice to him/her is “get a database”.
Re. Dic.Items() and Dic.Keys() are ARRAYS!
You missed the point. If you need to output to a range – don’t use dictionaries. Use RemoveDuplicates. If you want to work with the data as an array – Dic.Items() IS an array – just use as is.
@Craig. Weird. Because it takes a full 2 minutes ten seconds when I fill columns A to C with this:
=CHAR(RANDBETWEEN(65,90))& RANDBETWEEN(1,99)
…and then run this:
Maybe it’s a version or computer issue? I’ll email you my file.
Hi Dick
Thanks for the help. Please set the dic.Keys() and dic.Items() back. Here’s why. To be precise – these aren’t arrays. They are METHODS that RETURN arrays, similar to Split(). So if we intend to use the dic.Keys() or dic.Items() methods repeatedly, we should assign them to arrays so as to not incur the function overhead. Like so (assumes v is declared as a variant or variant array and dic has already been built):
V = dic.Keys()
debug.print v(0), dic.Keys()(0)
@Jeff – Try setting Application.Calculation = xlCalculationManual.
BTW – Here is a neat trick. Let’s assume we have a source table with 3 columns. After inputing the table into our dictionary using the coding in DicRow from my first post:
Dic(Row.Cells(1)) = Row
We can put the entire row into a range with one line like so:
[A1].Resize(1,3) = dic.Items()(0)
Makes no difference on my PC. I get lots and lots of screen flickering, and it takes ages. Maybe it’s an addin issue or something?
@Jan Karel: snb’s intent with his code has become a bit more clear to me: As written, his code looks for the last occurring duplicate items in column A of the table, and returns the whole row. So if we feed it this:
…it will return these rows:
Meaning we’d need to change your code slightly to do what he wants. And also meaning we don’t need to concatenate the varInput(i, 1) & “|” & varInput(i, 2) bit on the line cCol.Add varInput(i, 1) , varInput(i, 1) & “|” & varInput(i, 2)
Also note that you don’t need the Count = 1 line, and in fact at the beginning we want Count = 0 as you have coded it up, otherwise you get a blank line right at the beginning of your output.
Which leaves us with this even faster version:
@Jeff
Got your spreadsheet. It’s the randomness. Not the data size. Your data has more unique values. It is also why Revision_A2() is so fast. For each result, check not only the time but the number of unique values returned.
It’s actually a combination of the number of unique values, and the crap algorithm that Excel’s Remove Duplicates uses. To prove it, put =CHAR(RANDBETWEEN(65,90))& RANDBETWEEN(1,99999) in Column A, then paste special values. Run the Remove Duplicates algorythm. It takes a while.
Now do that again, but sort it Z to A. Takes much longer.
Now,do it again, but sort it A to Z before you run Excel’s Remove Duplicates. This time it takes no time at all.
Refer to the table I added at the bottom of my original article.
@Jeff Weir
There’s a file attached to the webpage to illustrate the examples.
http://www.snb-vba.eu/bestanden/__VBA_dictionaries_voorbeelden_en.xls
You will see that your interpretation doesn’t match what the example is all about.
Your quote:
‘If you feed an entire table row by row to the dictionary using the .item property, then the dictionary automatically uses the first item in that array as the key, and stores the entire line as the item.’
Can you show the code to do this ?
Since the ‘key’ is a required argument in the property item, I don’t see how it can be attributed automatically to a new item.
You will see that your interpretation doesn’t match what the example is all about. Maybe I haven’t made my interpretation clear. Put the string “First Record for aa1” in Unique!B2 and “Last record for aa1” in Unique!B18 and run your code. You will see that out of all the records with the key aa1, the “Last Record” one gets returned. I.e. if there are duplicate records, the last one gets returned.
Can you show the code to do this ? No I can’t. Because it doesn’t. I misinterpreted something :-)
If you didn’t want the last matching item, then much simpler and faster to use this:
Sub M_remove_duplicate_records_2() Dim rngData As Range Dim rngDest As Range Dim timetaken As Date timetaken = Now() Set rngData = Sheets("Unique").Cells(1).CurrentRegion Set rngDest = Sheets("Unique").Cells(4).Resize(rngData.Rows.Count, 2) rngDest.Value = rngData.Value rngDest.RemoveDuplicates Columns:=1, Header:=xlNo End Sub