A few weeks ago I was struggling with fixed width text files. Remember 1995? Me neither, but I’m living it every day. I happened upon a stackoverflow.com post that dealt with using ADO for this purpose. I don’t remember the post, so no link. It did, however, lead me to this MSDN article, which was very helpful.
If you haven’t been following along, I wrote a post about creating a sample fixed-width file and one about importing said file. This post is about importing that file with ADO. You may remember ADO from such database objects as Connection, Command, and Recordset. But, like me, you may never have considered using to import text files; or even knew that it could.
Before I get into the specifics, there are two things that endeared me to this method. First, it allows me to only import the data I want and easily ignores headers, totals, and other non-record data. Second, it’s super fast. I had a huge text file that took several minutes to read using the Input$ function. I got it down to 90 seconds using ADO. Ninety seconds still stinks, but it beats having to get a coffee every time the code runs. The bonus third reason I love ADO is that I can replicate it for different text files easily. Usually, fixed width text files are not arranged as normalized data, so there are some challenges. But I went from setting this up for one specific report to a dozen reports very quickly. Let’s see how it’s done.
Go read the MSDN article if you want the specifics, but basically you need a file called Schema.ini that tells ADO what’s what in your file. I don’t take a crap without a class module, so we’ll be using class modules here. Didn’t this use to be a family friendly blog?
If you couldn’t tell, the text file in question contains transactions from a general ledger. That means I need a Transaction class to hold each of them. Using the column headers from the file, I create a CTransaction class module.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Option Explicit Public TransactionID As Long Public Entry As String Public Period As Long Public PostDate As Date Public GLAccount As String Public Description As String Public Srce As String Public Cflow As Boolean Public Ref As String Public Post As Boolean Public Debit As Double Public Credit As Double Public Alloc As Boolean |
My VBHelpers add-in quickly converts those to properties and creates a CTransactions parent class. Next, I create an MEntryPoints standard module and insert the following code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Public Sub ImportGLTransactions() Dim clsTransactions As CTransactions Dim sh As Worksheet Dim sFile As String sFile = Application.GetOpenFilename("*.txt, *.txt") If sFile <> "False" Then Set clsTransactions = New CTransactions clsTransactions.FillFromFile sFile Set sh = Workbooks.Add.Sheets(1) clsTransactions.WriteToRange sh.Range("A1") End If End Sub |
I don’t have a FillFromFile method or a WriteToRange method, but I like to write my main procedure as if I already had those. You’ll need a reference to Microsoft ActiveX Data Objects 2.8 Library (although any version close to that will do). The FillFromFile method is pretty simple. It creates and ADO Connection and an ADO Recordset, then loops through the recordset adding CTransaction instances as it reads them in. It’s treating our text file as if it’s a database with field names and everything.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
Public Sub FillFromFile(ByVal sFile As String) Dim adCn As ADODB.Connection, adRs As ADODB.Recordset Dim vaConn As Variant, aSql(1 To 4) As String Dim sPATH As String Dim clsTransaction As CTransaction sPATH = Replace$(sFile, Dir$(sFile), vbNullString) 'We'll talk about this line later MakeSchema sFile, sPATH, Me.Schema 'Create a connection string and SQL statement vaConn = GetConnectionString(sPATH) aSql(1) = "SELECT" aSql(2) = Join(Me.Columns, ",") aSql(3) = "FROM [" & Dir$(sFile) & "]" aSql(4) = "WHERE PostDate Like ""[0-1][0-9]/[0-9][0-9]/[0-9][0-9][0-9][0-9]""" 'Open the connection and the recordset Set adCn = New ADODB.Connection adCn.Open Join(vaConn, ";") Set adRs = New ADODB.Recordset adRs.Open Join(aSql, Space(1)), adCn, adOpenStatic, adLockReadOnly, adCmdText 'Loop through the rs and create CTransaction instances If Not adRs.BOF And Not adRs.EOF Then Do While Not adRs.EOF Set clsTransaction = New CTransaction clsTransaction.FillFromRecordset adRs Me.Add clsTransaction adRs.MoveNext Loop End If adRs.Close adCn.Close End Sub |
We’ll hold off on how to create the Schema file for now. The Connection string is created with this little utility. You pass in the path and returns an array of strings ready to be joined.
|
1 2 3 4 5 6 7 8 9 10 11 |
Function GetConnectionString(ByVal sPATH As String) As Variant Dim aConn(1 To 3) As String aConn(1) = "Provider=Microsoft.Jet.OLEDB.4.0" aConn(2) = "Data Source=" & sPATH aConn(3) = "Extended Properties=""text;HDR=No;FMT=FixedLength""" GetConnectionString = aConn End Function |
I’ve recently starting using arrays and Joins to concatenate strings of any length. I find it makes the code much more readable and manageable once you get used to it. Let’s talk about that SQL statement. In Schema.ini, I’ve defined column names and column widths. We’ll look at it in a moment. The SQL statement selects all the columns from the text file based on some criteria. The first section of the SQL statement is the SELECT keyword. For the second section, I have a property that returns an array of columns. You could just as easily use “SELECT * FROM”, but I was recently shown the benefit of following the never-select-astrisk rule, so I’m trying to be good.
|
1 2 3 4 5 |
Public Property Get Columns() As Variant Columns = Array("Entry", "Period", "PostDate", "GLAccount", "Description", "Srce", "Cflow", "Ref", "Post", "Debit", "Credit", "Alloc") End Property |
Just an array of column names used in the SQL statment and in Schema.ini. The third section of the SQL statement is the FROM keyword followed by the file name in brackets. The Dir$ function strips the path out of the fullname and returns only the file name. You don’t need the path in the SQL statement because Schema.ini is in the same directory as the text file. It has to be, so it’s not looking anywhere else.
The final section of the SQL statement is the WHERE clause. This is where you have to get a little creative. As I scan down my text file, I need to find some characteristic of “good” rows that is not present in “bad” rows. For this example, it was pretty easy. Every row that I want has a real date in PostDate and every row that I don’t want doesn’t. They aren’t all that easy. Would you like to see some examples of WHERE clauses I’ve used? Well, would you?
|
1 2 3 4 5 6 |
aSql(4) = "WHERE (Tax Like ""__/__/____"" And Not(IsNull(Vendor))) Or Account Like ""[1-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]""" aSql(4) = "WHERE PaymentDate Like ""__/__/____"" And Not DiscountAmount Like ""%[ ][ ].00""" aSql(4) = "WHERE PostDate Like ""__/__/____"" Or GLAccount Like ""[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]""" aSql(4) = "WHERE InvoiceDate Like ""__/__/____"" AND ItemID <> ""Invoice Totals""" aSql(4) = "WHERE Kitted = ""YES"" Or Kitted = ""NO""" aSql(4) = "WHERE TranDate Like ""__/__/____"" Or (LotNo Like ""[A-Z][A-Z]%"" And TranDate Like "" [A-Z]%"" And Not LotNo Like ""Item ID%"")" |
Some of those are pretty gnarly. Our example file has lots of options, not just PostDate. We have three Yes/No fields and we could use any of those. It’s pretty unlikely that header information or totals rows are going to have a Yes or No in that same position. The idea is only get the rows you want. For some of the dates I used "__/__/____" and I think it’s pretty safe. But for this example, I used "[0-1][0-9]/[0-9][0-9]/[0-9][0-9][0-9][0-9]" which is a little more specific.
With a good connection string and SQL statement, I open the connection, open the recordset, and start looping. There’s not much to filling the CTransaction class via the FillFromRecordset method. It uses an Nz function that I wrote to avoid Null problems and return a default. For numbers and dates, I specify that I want to return a zero in place of a Null. For strings, it automatically returns vbNullString. The FillFromRecordset procedure is a method in CTransaction. The Nz function is in a standard module.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
Public Sub FillFromRecordset(ByRef adRs As ADODB.Recordset) Me.Entry = Nz(adRs.Fields("Entry")) Me.Period = Nz(adRs.Fields("Period"), 0) Me.PostDate = Nz(adRs.Fields("PostDate"), 0) Me.GLAccount = Nz(adRs.Fields("GLAccount")) Me.Description = Nz(adRs.Fields("Description")) Me.Srce = Nz(adRs.Fields("Srce")) Me.Cflow = Nz(adRs.Fields("Cflow")) = "Yes" Me.Ref = Nz(adRs.Fields("Ref")) Me.Post = Nz(adRs.Fields("Post")) = "Yes" Me.Debit = Nz(adRs.Fields("Debit"), 0) Me.Credit = Nz(adRs.Fields("Credit"), 0) Me.Alloc = Nz(adRs.Fields("Alloc")) = "Yes" End Sub Function Nz(fldTest As ADODB.Field, _ Optional vDefault As Variant) As Variant If IsNull(fldTest.Value) Then If IsMissing(vDefault) Then Select Case fldTest.Type Case adBSTR, adGUID, adChar, adWChar, adVarChar, adVarWChar Nz = vbNullString Case Else Nz = 0 End Select Else Nz = vDefault End If Else Nz = fldTest.Value End If End Function |
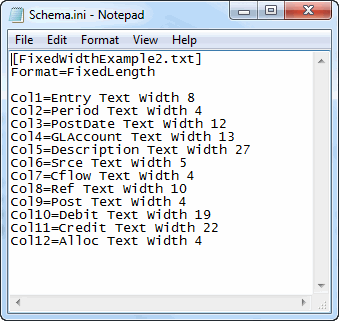
Now on to Schema.ini, at long last. I have a MakeSchema procedure in a standard module that simply creates the file where it’s supposed to. One of the arguments to MakeSchema is a string for the contents of the file. That comes from the Schema property of the CTranscations class (shown as Me.Schema in the FillFromFile method above). The Schema property takes the columns from the Columns property and puts them together with column widths to create the string.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Public Property Get Schema() As String Dim aReturn() As String Dim vaNames As Variant Dim vaWidths As Variant Dim i As Long vaNames = Me.Columns vaWidths = Array(8, 4, 12, 13, 27, 5, 4, 10, 4, 19, 22, 4) ReDim aReturn(LBound(vaNames) To UBound(vaNames)) For i = LBound(vaNames) To UBound(vaNames) aReturn(i) = "Col" & i + 1 & "=" & vaNames(i) & Space(1) & "Text Width" & Space(1) & vaWidths(i) Next i Schema = Join(aReturn, vbNewLine) End Property |
The widths array is simply how many characters wide each column is. The lines in my file are 132 characters long. Counting them is a pain. Usually, I grab a couple of representative lines from the text file and put them in a spreadsheet. Here’s how I came up with the column widths for this file.
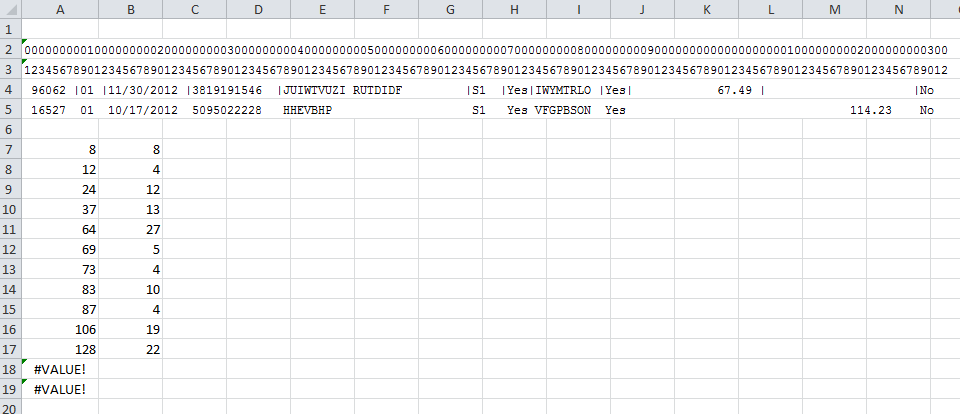
Lines 2-5 are Courier New 9pt and the first two lines are typed – no fancy formula to get those numbers. I like to get a couple of representative lines so I don’t miss anything. Then I go put pipes where I want the column breaks to be and put this formula in A7
=FIND("|",$A$4,A6+1)
and fill down until I get an error. Column B is just the difference. Finally, the MakeSchema utility takes that string and puts into a file.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Public Sub MakeSchema(ByVal sFile As String, ByVal sPATH As String, ByVal sCols As String) Dim lFile As Long Dim aWrite(1 To 4) As String Const sSCHEMA As String = "Schema.ini" aWrite(1) = "[" & Dir$(sFile) & "]" aWrite(2) = "Format=FixedLength" aWrite(3) = vbNullString aWrite(4) = sCols lFile = FreeFile Open sPATH & sSCHEMA For Output As lFile Print #lFile, Join(aWrite, vbNewLine) Close lFile End Sub |
And the Schema.ini file looks like this:
The final piece is writing all of the CTransaction objects to a range. The CTransactions collection class has a WriteToRange method that calls an OutputRange property. It’s pretty straightforward.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
Public Sub WriteToRange(rStart As Range) Dim vaWrite As Variant vaWrite = Me.OutputRange rStart.Resize(UBound(vaWrite, 1), UBound(vaWrite, 2)).Value = vaWrite rStart.CurrentRegion.EntireColumn.AutoFit End Sub Public Property Get OutputRange() As Variant Dim aReturn() As Variant Dim clsTransaction As CTransaction Dim lCnt As Long Dim vaHead As Variant Dim i As Long ReDim aReturn(1 To Me.Count + 1, 1 To 12) vaHead = Me.Columns lCnt = lCnt + 1 For i = LBound(vaHead) To UBound(vaHead) aReturn(lCnt, i + 1) = vaHead(i) Next i For Each clsTransaction In Me lCnt = lCnt + 1 With clsTransaction aReturn(lCnt, 1) = "'" & .Entry aReturn(lCnt, 2) = .Period aReturn(lCnt, 3) = .PostDate aReturn(lCnt, 4) = "'" & .GLAccount aReturn(lCnt, 5) = "'" & .Description aReturn(lCnt, 6) = "'" & .Srce aReturn(lCnt, 7) = .Cflow aReturn(lCnt, 8) = "'" & .Ref aReturn(lCnt, 9) = .Post aReturn(lCnt, 10) = .Debit aReturn(lCnt, 11) = .Credit aReturn(lCnt, 12) = .Alloc End With Next clsTransaction OutputRange = aReturn End Property |
I put apostrophes in front of the strings so they don’t get converted just because they look like a number or a date. And when I’m done, I sum up the Debit column and compare it to the text file.
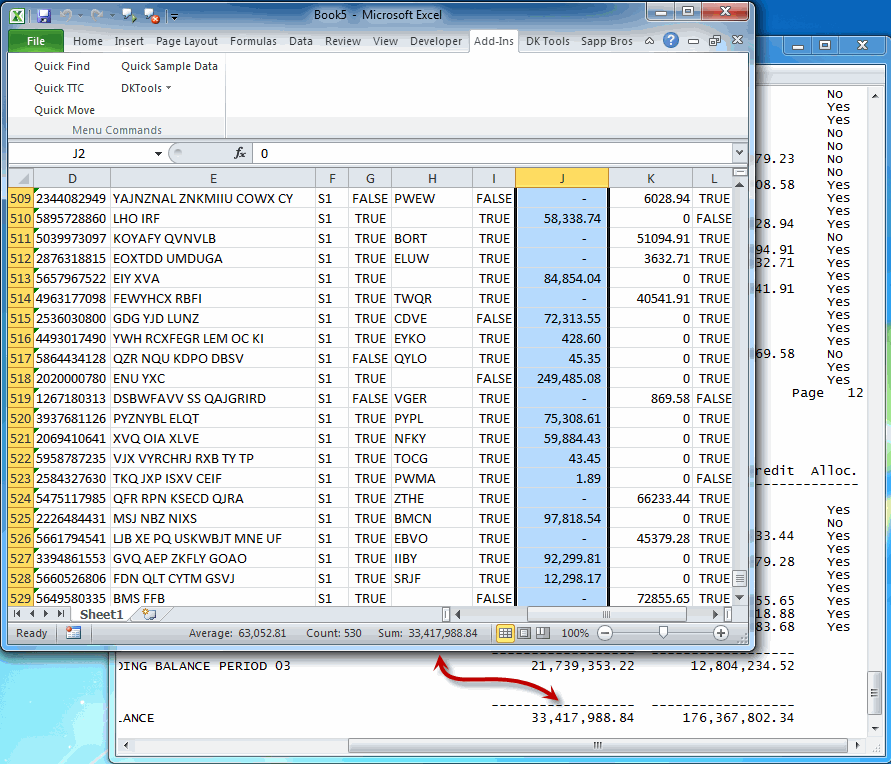
It’s a match! I must have done something right. No comments for you accountants about how my debits don’t equal my credits. You try to make fake data this internally consistent. :)
![]() You can download FixedWidthADO.zip
You can download FixedWidthADO.zip
Very impressive. Also very complicated. I know that Excel is your hammer of choice (mine too!), but I have to wonder if it doesn’t make more sense to just use a dedicated text import program and be done with it. Monarch would handle this quite easily and more robustly. Heck, even if you insist on using Excel, you can always use the object model to call it into being in the background.
I do love my ADO, though. I will definitely keep this in mind if I ever have to deliver a packaged solution and cannot rely on external functionality.
Definitely I would use Monarch. It’s pricey though. I sure would like to see their algorithm.
Wouldn’t this be sufficient ?
Sub M_snb()sn = Filter(Filter(Split(CreateObject("scripting.filesystemobject").opentextfile("G:\OF\0_fixedwidth_example_001.txt").readall, vbCrLf), Space(60), False), "/")
y = InStr(sn(0), " ")
For j = 1 To Len(sn(0))
For jj = 1 To UBound(sn)
If Mid(sn(jj), y, 1) <> " " Then Exit For
Next
If jj = UBound(sn) + 1 Then c00 = c00 & Mid(sn(0), Len(c00) + 1, y - Len(c00) - 1) & "|"
y = y + InStr(Mid(sn(0), y + 1), " ")
If y = Len(sn(0)) Then Exit For
Next
c00 = c00 & Right(sn(0), y - Len(c00))
For j = 10 To 2 Step -1
c00 = Replace(c00, String(j, "|"), "|" & Space(j - 1))
Next
sp = Split(c00, "|")
For j = 0 To UBound(sn)
c01 = ""
For jj = 0 To UBound(sp)
c01 = c01 & Mid(sn(j), Len(c01) + 1, Len(sp(jj))) & ","
Next
sn(j) = Left(c01, Len(sn(j)))
Next
CreateObject("scripting.filesystemobject").createtextfile("G:\OF\0_fixedwidth_example_001.csv").write Join(sn, vbCrLf)
Workbooks.Open "G:\OF\0_fixedwidth_example_001.csv"
End Sub
That didn’t work on my sample data
No harm done, just a slight amendment:
Sub M_snb()sn = Filter(Filter(Split(Replace(CreateObject("scripting.filesystemobject").opentextfile("G:\OF\0_fixedwidth_example_001.txt").readall, ",", ""), vbCrLf), Space(60), False), "/")
y = InStr(sn(0), " ")
For j = 1 To Len(sn(0))
For jj = 1 To UBound(sn)
If Mid(sn(jj), y, 1) <> " " Then Exit For
Next
If jj = UBound(sn) + 1 Then c00 = c00 & Mid(sn(0), Len(c00) + 1, y - Len(c00) - 1) & "|"
y = y + InStr(Mid(sn(0), y + 1), " ")
If y = Len(sn(0)) Then Exit For
Next
c00 = c00 & Right(sn(0), y - Len(c00))
For j = 10 To 2 Step -1
c00 = Replace(c00, String(j, "|"), "|" & Space(j - 1))
Next
sp = Split(c00, "|")
For j = 0 To UBound(sn)
c01 = ""
For jj = 0 To UBound(sp)
c01 = c01 & Mid(sn(j), Len(c01) + 1, Len(sp(jj))) & ","
Next
sn(j) = Left(c01, Len(sn(j)))
Next
CreateObject("scripting.filesystemobject").createtextfile("G:\OF\0_fixedwidth_example_001.csv").write Join(sn, vbCrLf)
Workbooks.Open "G:\OF\0_fixedwidth_example_001.csv"
End Sub
But if you insist on using ADODB and a schema.ini file:
Sub M_snb_007()c00 = "G:\OF\"
c01 = c00 & "0_fixedwidth_example_001.txt"
c02 = "0_fixedwidth_example_002.txt"
c03 = c00 & "schema.ini"
With CreateObject("scripting.filesystemobject")
sn = Filter(Filter(Split(Replace(.opentextfile(c01).readall, ",", ""), vbCrLf), Space(60), False), "/")
.createtextfile(c00 & c02).write sn(0) & vbCrLf & Join(sn, vbCrLf)
y = InStr(sn(0), " ")
For j = 1 To Len(sn(0))
For jj = 1 To UBound(sn)
If Mid(sn(jj), y, 1) <> " " Then Exit For
Next
If jj = UBound(sn) + 1 Then c04 = c04 & Mid(sn(0), Len(c04) + 1, y - Len(c04) - 1) & "|"
y = y + InStr(Mid(sn(0), y + 1), " ")
If y = Len(sn(0)) Then Exit For
Next
c04 = c04 & Right(sn(0), y - Len(c03))
For j = UBound(Split(c04, "|")) To 2 Step -1
c04 = Replace(c04, String(j, "|"), "|" & Space(j - 1))
Next
sp = Split(c04, "|")
For j = 0 To UBound(sp)
sp(j) = "Col" & j + 1 & "=veld" & j + 1 & " Text Width " & Len(sp(j)) + 1
Next
.createtextfile(c03).write "[" & c02 & "]" & vbCrLf & "Format=Fixedlength" & String(2, vbCrLf) & Join(sp, vbCrLf)
End With
With New ADODB.Recordset
.Open "SELECT * FROM " & c02, "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" & c00 & ";Extended Properties=""text;HDR=yes;FMT=FixedLength""", 3, 3, 1
Cells(1).CopyFromRecordset .DataSource
End With
End Sub
Odd. I thought everyone was using ADO to read text files with SQL.
Meanwhile, a quick tip: the ADODB.Recordset has a save method, which writes to an XML file or to a tab-delimited text file. This is not, of itself, terribly interesting: but the flipside of that is that the ADODB.Recordset object has a native ‘Open’ method that loads from a file:
Dim rst As ADODB.Recordset
Set rst = New ADODB.Recordset
rst.Open “C:\Temp\SysLog.txt”
rst.Filter = “[msgType]=’ERROR'”
If the file’s tab-delimited, that’s it. All of it. Not quite what you want for fixed-width files, but kinda useful.
You may find that you can only read files with a .txt and .csv extension using the Jet 4.0 driver: by default, other file extensions are disabled, no matter what you specify in the Schema.
Here’s what to do if you’re trying to read a file with a .log extension and you prefer not to rename it:
‘ Can this workstation read .log files using the SQL text driver?
‘ An explanation of this procedure is available here:
‘ http://msdn.microsoft.com/en-us/library/ms974559.aspx
Dim strFileKey As String
Dim strExt As String
Dim objShell As Object ‘ As IWshRuntimeLibrary.WshShell ‘
Set objShell = CreateObject(“WScript.Shell”) ‘ New IWshRuntimeLibrary.WshShell
‘
If objShell Is Nothing Then
Shell “Regsvr32.exe /s wshom.ocx”, vbHide
Set objShell = CreateObject(“WScript.Shell”)
End If
If Not objShell Is Nothing Then
strFileKey = objShell.RegRead(“HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\Text\DisabledExtensions”)
If strFileKey <> “” Then
strExt = “log”
If InStr(1, strFileKey, strExt, vbTextCompare) < 1 Then objShell.RegWrite _ "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\Text\DisabledExtensions", _ strFileKey & "," & strExt, _ "REG_SZ" End If End If End If
Alternatively, could specify the ODBC text driver in the connection string for your ADO connection:
‘
strConn = “”
strConn = strConn & “Driver={Microsoft Text Driver (*.txt; *.csv)};”
strConn = strConn & “Extensions=asc,csv,tab,txt,log,dat;”
strConn = strConn & “Dbq=” & strFolder & “;”
strConn = strConn & “Extended Properties=” & Chr(34) & “text;HDR=NO;IMEX=2;MAXSCANROWS=0;” & Chr(34) & “;”
‘
Also: ninety seconds?
Were you reading this across the network? It’s always faster to use the file system to copy the file across to a local folder and read in the file from there, even when using ADODB.
No it was local. It was a few thousand pages.
Hi Dick,
Not too well versed with the solution above. But highly frustrated with the same issue.
Is it possible to customize the above solution ?
It would be quite handy if you can mention some simple steps. I would study the details, but that seems too technical and foreign.
I know everything has to use a class but what if it did not have to? {grin}
Instead of converting a table to a collection of objects and back to a table, how about using the range.copyfromrecordset method? Skip the part about working record by record. The real power of SQL is in working with entire tables at one go.
If you can do w/o the NZ function, all that should be required is
rs.open "SELECT...WHERE..."rng.copyfromrecordset rs
See http://msdn.microsoft.com/en-us/library/office/aa223845%28v=office.11%29.aspx
If you must use the NZ function, I don't know if one can specify a SQL UDF in the SQL for the rs.open method. It would be an interesting test but it's too late for it tonight. For more on a SQL UDF see http://msdn.microsoft.com/en-us/library/aa214363%28v=sql.80%29.aspx
Finally, I almost never use Array(). I prefer Split. A lot less work esp. all those quotes.
Columns = Split("Entry,Period,PostDate,GLAccount,Description,Srce,Cflow,Ref,Post,Debit,Credit,Alloc",",")I love the Split thing – I’ll be implementing that right away.
CopyFromRecordset would work great in this example, but it’s not typical for me. Nothing is really ‘typical’ though because they’re stupid text reports and not setup as data. In one case, I have a payables report that gets put into a Vendor class and an Invoice class. I couldn’t do that with CopyFromRecordset. In another case, each “record” is actually three lines on the report. As I’m looping through the recordset, I create one class every third line and fill it as I go.
The other downside to CopyFromRecordset is that all it does is copy from recordset (yes, it’s well named). In this example, my output is an Excel table, but in some other situation maybe it’s not. Maybe it’s creating financial statements or emails or html pages. With classes, of course, I can do anything with the data.
Having said all that, CopyFromRecordset is the better option for the example shown.
Tushar –
You could, of course, set all the nulls to zero (or empty string) in your SQL.
Of course, you can’t use the VBA NZ() function in SQL, let alone a UDF, unless you’re in a a JET environment with locally-available VB: but the native SQL IIF() function is slightly faster than NZ() in that environment, and whatever database driver you’re using will parse it.
SELECT
IIF([Entry] IS NULL, ”, [Entry]) AS [Entry],
IIF([Period] IS NULL, 0, [Period]) AS [Period]
FROM
tblMousetrap