Howdy folks. Jeff here, back from my summer holiday in the Coromandel Peninsula in the North Island of New Zealand, where I’ve been staring at this for the last 21 days:

For the next 344 I’ll be staring at this:
God, it’s good to be home.
A while back I answered this thread for someone wanting to identify any duplicate values found between 4 separate lists.
The way I understood the question, if something appears in each of the four lists, the Op wanted to know about it. If an item just appeared in 3 lists but not all 4, then they didn’t want it to be picked up. And the lists themselves might have duplicates within each list.
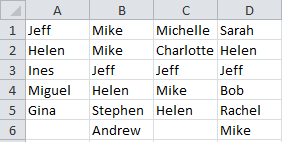
Say we’ve got these 4 lists:
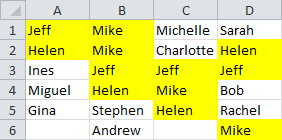
We can’t simply use Conditional Formatting, because that will include duplicate names that don’t appear in each and every column, such as ‘Mike’:
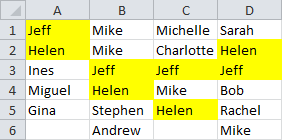
Rather, we only want names that appear in every column:
I wrote a routine that handled any number of lists, using two dictionaries and a bit of shuffling between them. And the routine allows users to select either a contiguous range if their lists are all in one block, or multiple non-contiguous ranges if they aren’t.
- The user gets prompted for the range where they want the identified duplicates to appear:
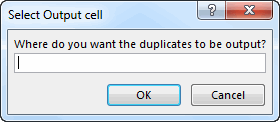
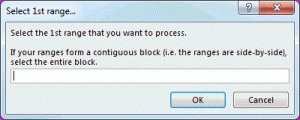
- Then they get prompted to select the first list. The items within that list get added to Dic_A. (If they select more than one columns, the following steps get executed automatically).
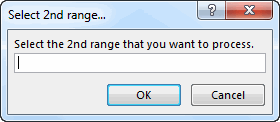
- Next they get prompted to select the 2nd list, at which point the code attempts to add each new item to Dic_A. If an item already exists in Dic_A then we know it’s a duplicate between lists, and so we add it to Dic_B. At the end of this, we clear Dic_A. Notice that any reference to selecting a contiguous range has been dropped from the InputBox:
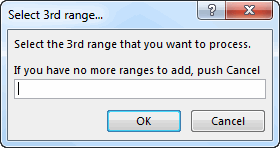
- When they select the 3rd list, then it attempts to add each new item to Dic_B, and if an error occurs, then we know it’s a duplicate between lists, and so we add it to Dic_A. At the end of this, we clear Dic_B. We carry on in this manner until the user pushes Cancel (and notice now that the InputBox message tells them to push cancel when they’re done):
Pretty simple: just one input box, an intentional infinite loop, and two dictionaries that take turns holding the current list of dictionaries. Hours of fun.
Only problem is, I had forgotten to account for the fact that there might be duplicates within a list. The old code would have misinterpreted these duplicates as between-list duplicates, rather than within-list duplicates. The Op is probably completely unaware, and probably regularly bets the entire future of his country’s economy based on my bad code. Oops.
I’ve subsequently added another step where a 3rd dictionary is used to dedup the items in the list currently being processed. Here’s the revised code. My favorite line is the Do Until “Hell” = “Freezes Over” one.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
Sub DuplicatesBetweenLists() Dim rngOutput As Range Dim dic_A As Object Dim dic_B As Object Dim dic_Output As Object Dim lng As Long Dim lngRange As Long Dim varItems As Variant Dim strMessage As String varItems = False On Error Resume Next Set varItems = Application.InputBox _ (Title:="Select Output cell", _ Prompt:="Where do you want the duplicates to be output?", Type:=8) If Err.Number = 0 Then 'user didn't push cancel On Error GoTo 0 Set rngOutput = varItems Set dic_A = CreateObject("Scripting.Dictionary") Set dic_B = CreateObject("Scripting.Dictionary") Set dic_Output = CreateObject("Scripting.Dictionary") lngRange = 1 Do Until "Hell" = "Freezes Over" 'We only want to exit the loop once the user pushes Cancel, ' or if their initial selection was a 2D range Select Case lngRange Case 1: strMessage = vbNewLine & vbNewLine & "If your ranges form a contiguous block (i.e. the ranges are side-by-side), select the entire block." Case 2: strMessage = "" Case Else: strMessage = vbNewLine & vbNewLine & "If you have no more ranges to add, push Cancel" End Select varItems = Application.InputBox(Title:="Select " & lngRange & OrdinalSuffix(lngRange) & " range...", _ Prompt:="Select the " & lngRange & OrdinalSuffix(lngRange) & " range that you want to process." & strMessage, _ Type:=8) If VarType(varItems) = vbBoolean Then lngRange = lngRange - 1 If lngRange = 0 Then GoTo errhandler: Exit Do Else: DuplicatesBetweenLists_AddToDictionary varItems, lngRange, dic_A, dic_B If UBound(varItems, 2) > 1 Then lngRange = lngRange - 1 Exit Do 'Data is in a contigous block End If End If Loop 'Write any duplicate items back to the worksheet. If lngRange Mod 2 = 0 Then Set dic_Output = dic_B Else: Set dic_Output = dic_A End If If dic_Output.Count > 0 Then If dic_Output.Count < 65537 Then rngOutput.Resize(dic_Output.Count) = Application.Transpose(dic_Output.Items) Else 'The dictionary is too big to transfer to the workheet ' because Application.Transfer can't handle more than 65536 items. ' So we'll transfer it to an appropriately oriented variant array, ' then transfer that array to the worksheet WITHOUT application.transpose ReDim varOutput(1 To dic_Output.Count, 1 To 1) For lng = 1 To dic_Output.Count varOutput(lng, 1) = dic_Output.Item(lng) Next lng rngOutput.Resize(dic_Output.Count) = varOutput End If 'If dic_Output.Count < 65537 Then Else: MsgBox "There were no numbers common to all " & lngRange & " columns." End If 'If dic_Output.Count > 0 Then End If 'If VarType(varItems) <> vbBoolean Then 'User didn't cancel 'Cleanup Set dic_A = Nothing Set dic_B = Nothing Set dic_Output = Nothing errhandler: End Sub Private Function DuplicatesBetweenLists_AddToDictionary(varItems As Variant, ByRef lngRange As Long, ByVal dic_A As Object, ByVal dic_B As Object) Dim lng As Long Dim dic_dedup As Object Dim varItem As Variant Dim lPass As Long Set dic_dedup = CreateObject("Scripting.Dictionary") For lPass = 1 To UBound(varItems, 2) If lngRange = 1 Then 'First Pass: Just add the items to dic_A For lng = 1 To UBound(varItems) If Not dic_A.exists(varItems(lng, 1)) Then dic_A.Add varItems(lng, 1), varItems(lng, 1) Next Else: ' Add items from current pass to dic_Dedup so we can get rid of any duplicates within the column. ' Without this step, the code further below would think that intra-column duplicates were in fact ' duplicates ACROSS the columns processed to date For lng = 1 To UBound(varItems) If Not dic_dedup.exists(varItems(lng, lPass)) Then dic_dedup.Add varItems(lng, lPass), varItems(lng, lPass) Next 'Find out which Dictionary currently contains our identified duplicate. ' This changes with each pass. ' * On the first pass, we add the first list to dic_A ' * On the 2nd pass, we attempt to add each new item to dic_A. ' If an item already exists in dic_A then we know it's a duplicate ' between lists, and so we add it to dic_B. ' When we've processed that list, we clear dic_A ' * On the 3rd pass, we attempt to add each new item to dic_B, ' to see if it matches any of the duplicates already identified. ' If an item already exists in dic_B then we know it's a duplicate ' across all the lists we've processed to date, and so we add it to dic_A. ' When we've processed that list, we clear dic_B ' * We keep on doing this until the user presses CANCEL. If lngRange Mod 2 = 0 Then 'dic_A currently contains any duplicate items we've found in our passes to date 'Test if item appears in dic_A, and IF SO then add it to dic_B For Each varItem In dic_dedup If dic_A.exists(varItem) Then If Not dic_B.exists(varItem) Then dic_B.Add varItem, varItem End If Next dic_A.RemoveAll dic_dedup.RemoveAll Else 'dic_B currently contains any duplicate items we've found in our passes to date 'Test if item appear in dic_B, and IF SO then add it to dic_A For Each varItem In dic_dedup If dic_B.exists(varItem) Then If Not dic_A.exists(varItem) Then dic_A.Add varItem, varItem End If Next dic_B.RemoveAll dic_dedup.RemoveAll End If End If lngRange = lngRange + 1 Next End Function Function OrdinalSuffix(ByVal Num As Long) As String 'Code from http://www.cpearson.com/excel/ordinal.aspx Dim N As Long Const cSfx = "stndrdthththththth" ' 2 char suffixes N = Num Mod 100 If ((Abs(N) >= 10) And (Abs(N) <= 19)) _ Or ((Abs(N) Mod 10) = 0) Then OrdinalSuffix = "th" Else OrdinalSuffix = Mid(cSfx, _ ((Abs(N) Mod 10) * 2) - 1, 2) End If End Function |
Wouldn’t this suffice ?
Sub M_snb()
sn = Cells(1).CurrentRegion
For Each cl In sn
If (InStr(" " & Join(Application.Transpose(Application.Index(sn, 0, 1))) & " ", " " & cl & " ") > 0) * (InStr(" " & Join(Application.Transpose(Application.Index(sn, 0, 2))) & " ", " " & cl & " ") > 0) * (InStr(" " & Join(Application.Transpose(Application.Index(sn, 0, 3))) & " ", " " & cl & " ") > 0) * (InStr(" " & Join(Application.Transpose(Application.Index(sn, 0, 4))) & " ", " " & cl & " ") > 0) And InStr("_" & c00 & "_", "_" & cl & "_") = 0 Then c00 = c00 & "_" & cl
Next
MsgBox Mid(c00, 2)
End Sub,
On this small dataset, yes. On the Op’s larger data set, not anytime soon. He had 4 columns with up to 2500 rows in each of them. Your approach takes 2 minutes. Using my approach above takes seconds, including the time taken to select the 4 ranges.
Based on your new information:
Sub M_snb()sn = Cells(1).CurrentRegion
ReDim sp(UBound(sn, 2) - 1)
For j = 1 To UBound(sn, 2)
sp(j - 1) = Application.Index(sn, 0, j)
Next
With CreateObject("scripting.dictionary")
For Each cl In sn
If Not .exists(cl) Then
For j = 0 To UBound(sp)
If IsError(Application.Match(cl, sp(j), 0)) Then Exit For
Next
If j > UBound(sp) Then x0 = .Item(cl)
End If
Next
MsgBox Join(.keys, vbLf)
End With
End Sub
On second thought we can reduce it to:
Sub M_snb()sn = Cells(1).CurrentRegion
ReDim sp(UBound(sn, 2) - 1)
For j = 1 To UBound(sn, 2)
sp(j - 1) = Application.Index(sn, 0, j)
Next
With CreateObject("scripting.dictionary")
For Each cl In sp(0)
If Not .exists(cl) Then
For j = 0 To UBound(sp)
If IsError(Application.Match(cl, sp(j), 0)) Then Exit For
Next
If j > UBound(sp) Then x0 = .Item(cl)
End If
Next
MsgBox Join(.keys, vbLf)
End With
End Sub
On third thought to:
testing only the values in the first range to the other ranges.
Sub M_snb()sn = Cells(1).CurrentRegion
ReDim sp(UBound(sn, 2) - 1)
For j = 1 To UBound(sn, 2)
sp(j - 1) = Application.Index(sn, 0, j)
Next
With CreateObject("scripting.dictionary")
For Each cl In sp(0)
If Not .exists(cl) Then
For j = 1 To UBound(sp)
If IsError(Application.Match(cl, sp(j), 0)) Then Exit For
Next
If j > UBound(sp) Then x0 = .Item(cl)
End If
Next
MsgBox Join(.keys, vbLf)
End With
End Sub
It might even be done with a oneliner:
Sub m_snb()MsgBox Join(Filter(Application.Transpose([if((countif(B1:B2000,A1:A2000)=0),"~",if(countif(C1:C2000,A1:A2000)=0,"~",if(countif(D1:D2000,A1:A2000)=0,"~",A1:A2000)))]), "~", False), vbLf)
End Sub
You might find this one-liner code for determining the ordinal suffix to be of interest…
Function Ordinal(Number As Long) As String
Ordinal = Mid$(“thstndrdthththththth”, 1 – 2 * ((Number) Mod 10) * (Abs((Number) Mod 100 – 12) > 1), 2)
End Function
snb: That last routine doesn’t seem to work for me. I entered =RANDBETWEEN(1,2000) in the range A1:D2500, then ran both your code and mine. Mine returned 500 items, and yours returned 461. Looking at your data, some duplicates are definately missing, and other numbers get repeated.
I haven’t looked at your other listings yet.
@jeff
this method can’t contain duplicates, since it uses the dictionary.
Sub M_snb()sn = Cells(1).CurrentRegion
ReDim sp(UBound(sn, 2) - 1)
For j = 1 To UBound(sn, 2)
sp(j - 1) = Application.Index(sn, 0, j)
Next
With CreateObject("scripting.dictionary")
For Each cl In sp(0)
If Not .exists(cl) Then
For j = 1 To UBound(sp)
If IsError(Application.Match(cl, sp(j), 0)) Then Exit For
Next
If j > UBound(sp) Then x0 = .Item(cl)
End If
Next
MsgBox Join(.keys, vbLf)
End With
End Sub
Post your testfile somewhere so I can have a look.
I realised later you used the oneliner.
If the range is 2500 rows it might be practical to adapt the code to that range too.
I introduced a short condition to avoid duplicates:
Sub m_snb()MsgBox Join(Filter(Application.Transpose([if(countif(offset($A$1,,,row(A1:A2500)),A1:A2500)=1,if(countif(B1:B2500,A1:A2500)=0,"~",if(countif(C1:C2500,A1:A2500)=0,"~",if(countif(D1:D2500,A1:A2500)=0,"~",A1:A2500))),"~")]), "~", False), vbLf)
End Sub
Hi
If it is not necessary to highlight the value in every column then you can use the following formula in the conditional format
=SUM(COUNTIF(OFFSET($A1,0,COLUMN(INDIRECT(“$A$1:$C$1”)),6,1),$A1)*1)=3
If the value must exists in all four columns for this to be true, then you only need to test the values in the first column exist in the other three columns.
This will highlight the values in the first column where they exist in each of the other three columns, in your example this only returns Jeff & Helen.
NOTE: I only used indirect so that if columns are inserted to the left of the table the conditional formatting still works.
Robert
Hi snb. That’s cool…I never knew about the Filter method till now. Only thing is, I wouldn’t want to generalize your approach…as the range to be processed grows, this becomes increasingly slower in comparison to a dictionary. For instance, 5000 items takes 12 seconds, and 7500 items takes 27 seconds, whereas a dictionary does it pretty much instantly.
I’ve amended my original sub so that if the user selects a 2d range during the initial selection, the code knows that all the lists to be processed are within this range. So they no longer need to make multiple selections. But if they select a 1d range, then the code knows that the user will want to make further selections, so the input box keeps coming up till they push cancel. Have amended the original blog post accordingly.