IFERROR is a worksheet function that was introduced in Excel 2007. It’s a catch-all error handler that you can wrap around a formula and return a different value if the formula evaluates to an error. Like most people, I was happy to see it to avoid the old
=IF(ISNA(VLOOKUP(...)),"Not Found",VLOOKUP(...))
construct. Two VLOOKUPs in the same formula is terribly inefficient, so this new worksheet function is welcome. Or is it. I read this over at StackOverflow.
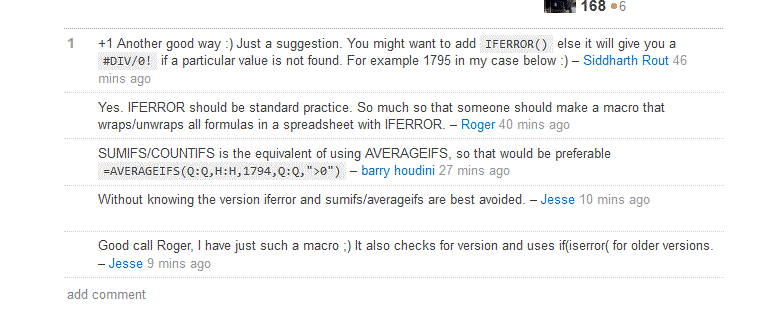
It nearly makes me weep. I can think of no better way to get incorrect results than by wrapping every formula in IFERROR. It got me thinking about IFERROR in general, so I went and read about at office.microsoft.com. Here are the examples they give.

More weeping. Boy, I’m emotional today. It’s just an illustration, I know, but consider this
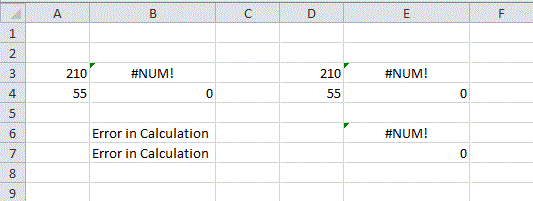
Microsoft’s method is on the left and mine is on the right. My formula is =IF(E3<>0,D3/E3,0). Microsoft’s example totally masks the fact that there’s an error in the first line. They’re trying to avoid a divide by zero error, but they’re using a sledge hammer on a push pin. If they want to catch more errors than just #DIV/0!, they should test for them explicitly.
As long as I’m writing about errors, another error handling construct that I dislike is this one.
=IF(ISERROR(VLOOKUP(...)),"Not Found",VLOOKUP(...))
I don’t like this because ISERROR will detect any kind of error when the only one that should be detected is NA. If there’s a #NUM! error in there, you’ll get the result “Not Found”, which is technically true but hardly helpful and sometimes damaging.
I’d like to have some guidelines about error checking in formulas. I’m the wrong guy to write these guidelines, but I’ll get the ball rolling.
- Don’t use error handling without a specific reason
- Test for the condition that would cause the error instead of error handling (examples: zero denominators, all IRR arguments with the same sign)
- Wrap the smallest piece of a formula with error handling that is possible
- Use the smallest scope error handling function possible (in order: ISNA, ISERR, ISERROR, IFERROR)
I’m sure you guys can poke some serious holes in that list, so please do. I guess my point is that errors are good. When you see an error returned in Excel, you know you made a mistake and you can fix it. If you don’t see it, you may not know and you may not fix it. Some errors are predictable and unavoidable, so we use the tools we have to deal with those errors in a responsible manner.
This is a nice feature if you are rolling out a workbook to a large audience that is mostly locked down and you want to keep the user interface clean. I would agree with the hammer vs pushpin argument though. The UI would be more usable if the formula maybe used the IFERROR as a catch all, but then tested for ISNA and Division by Zero to get the correct error message to the user: =IFERROR(, if(isna(), “Error Message 1”, if(, “Error message 2”, “Generic Error Message”))). That could get expensive if your workbook is formula heavy.
I’m with you all the way there Dick. There was recently a discussion on good and bad formula habits over at one of the LinkedIn groups. There was suggestion that a good formula should never yield an error. Rubbish!
Handling errors needlessly and everywhere is a bit like using On Error Resume Next at the top of a procedure. No accomplished VB(A) developer would do that.
I had the same reaction when I first saw IFERROR. It encompasses too many error conditions. Would have been nicer to:
1) Either an explicit IFxx for every ISxx error test or
2) Better: a 3rd argument that allowed one to specify which errors to look for. Something like IFERROR({formula}, {error result}, (ERRDIV+ERRNA)) or
3) In the spirit of the new approach to functions like SUMIFS, use IFERROR({formula}, {error-1 formula}, {error-1}, {error-2 formula}, {error-2},…). So, one could have IFERROR({formula},{rslt-1},ERRDIV+ERRNA, {rslt-2},ERRNUM}
Of course, given the focus on making Office more usable to people with less experience, 3 and 4 below are probably too complex.
Why not replace the error constants in 3 above with any boolean conditional? So,
4) IFS({formula}, {rslt-1}, {condition-1}, {rslt-2}, {condotion-2},…) Use this as in IFS(D2/D1-1,0,AND(D2=0,D1=0), NA(),D1=0)
To expand on error handling, I have the same problem with the use of 0 as a legitimate result to work around a divide by zero! IF(E1=0,0,E2/E1-1). Give me a break. If I introduce a new product and sales go from zero to 1 million units in 1 year, my year-over-year increase is 0%?
And, then there are the developers who create UDFs (or subroutines) that return the handful of error conditions that Excel supports (#NUM!, #VALUE!, etc). That might have made sense in the early 80’s but to mindlessly stick to those limited results in the 2010s?
I consider it to be the formula version “On Error Resume Next”. Is it dangerous? Quite. Can you get of of a jam with it? Yes.
Your 4 points are great advice as general guidelines. I would add a 5th: make the else results impossible or improbable and thus easy to spot. To make if even easier to spot a conditional format might also be helpful.
I would be OK with an IFERROR that allowed you to limit it to one error. Any error that you didn’t intentionally trap would get passed out of IFERROR and you could nest IFERRORs to trap more than one. Not the cleanest, but if you’re nesting seven IFERRORs it’s time to refactor.
There are, in my opinion, three mutually exclusive “correct” answers to zero denominators
Jon: Having an error value (#VALUE, #NUM, or in the cast of my newer UDFs #ERR:{error message}) would be easy to spot. {grin}
You make a valid point and it extends to data validation. In recent times I have moved away from data validation and instead use explicit errors.
Validate Mandatory Data
http://www.tushar-mehta.com/excel/newsgroups/validate_data/index.html
Tushar: The primary use use case for IFERROR, is on a vlookup where if data is missing, a default value is required to continue further calculations. I agree that error codes beat default values for general use.
This is a great topic. Dick, I’d add a fourth “correct” answer to zero denominators: “NA” – when the percent measurement doesn’t apply to some records in the dataset. For example, the percent of all trips to school by bus is “NA” for home-schooled kids, because they don’t take any trips to school.
The mathmetician in me argues that a divide by zero error could result in any (real or imaginary number) depending on the numerator. 0/0 can only be evaluate as the 2 numbers approch 0, If the number is similar to x/x then the answer should be 1, if it is similar to x^2/x then ti should be 0 if it is -x/x^2 then it should be – ininity etc!
I use iferror to wrap getpivotdata on dashboards, in that case the error (data not existing) should either be 0 or N/A depending on the situation, butagree with the rest of the points above.
With respect to #DIV/0 error, the typical scenario that I use to handle it is for variance analysis. Say on one account I have no budget, but there are actuals (sales for instance), and on another I have budget but no actuals. What I may wish to report is 100% favourable variance on one (i.e. having sales when not budgeted IS favourable), and -100% adverse variance on the other (i.e. I had a budget, but no sales).
This is quite typical when sales are forecasted in one area (e.g. cost centre, or GL account code), but allocated to another.
I hadn’t thought about -100%. Good one Jon.
I use IFERROR almost exclusively for reference functions such as VLOOKUP, where it may be more convenient and/or esthetically pleasing to see a result like “” than a #N/A error. Yes, using the old-school IF(ISNA(…)…) approach will work, and will trap only the particular error I am interested in, but I think it results in an easier-to-understand formula.
That said, I am very, very wary of using IFERROR on arithmetic calculations, mainly because for most of the arithmetic calcs I do, I need to know if there is an error condition :)
Ack, I think my text above got mistaken for an HTML tag :)
“…where it may be more convenient and/or esthetically pleasing to see a result like ‘no match’ than a #N/A error.”
To paraphrase an old saying, if you give people a hammer, they will see nails everywhere. Judicious use of IFERROR could make your spreadsheets quicker and cleaner – especially in the VLOOKUP case, where you want to avoid calling VLOOKUP twice. However, wrapping everything in IFERROR is just bad practice. I can see Microsoft implement a worksheet setting in the near future, to ignore all errors in formula results, and replace them with a ‘friendly’ message or, worse, a 0 or a blank.
@Sjoerd, that’s a downright dystopian prediction! “War is Peace” “Ignorance is Strength”
IFERROR is just the logical extension of IF(ISERROR). They’re both too broad.
#NULL! logic error
#DIV/0! runtime/contingent error
#VALUE! runtime/contingent error
#REF! logic error
#NAME? logic error
#NUM! runtime/contingent error
#N/A runtime/contingent error
All of these could result from users entering the particular error constant. If you have users like that, you have my sympathy because there’s not much you can do about them if their managers won’t fire ’em.
Aside from users entering errors intentionally or inadevertently, logic errors are errors which shouldn’t happen because they occur when inadequate safeguards are built into formulas.
#NULL! results from intersecting disjoint areas. I have yet to see well-designed spreadsheets which use range intersection. There’s no simple way to detect this from multiple range arguments. If it occurs, it should propagate as a warning that the developer/maintainer has work remaining to do.
#REF! results most often from indexing outside of ranges/arrays. There are efficient checks: INDEX(X,R[,C[,A]]) can be preceded by AND(AREAS(X)>=A,R=MEDIAN(0,R,ROWS(X)),C=MEDIAN(0,C,COLUMNS(X))). The other common reason is moving other cells onto cells referred to by formulas, in which case Excel replaces those range references with #REF!. Those errors should most definitely always propagate.
#NAME? results from referring to a nonexistent name. Just like the second case above for #REF!, #NAME? errors should always propagate.
The 3 errors above result from errors in the spreadsheet design rather than from data anomalies. In other words, due to things users can’t fix. If such errors occur, much better to display and propagate those errors to let everyone know they need fixing than to hide them with overly broad error trapping.
Runtime/contingent errors are errors which could occur due to data anomalies including but not limited to bad user entries. These should be EXPECTED to occur with some frequency, hence formulas need to check for expected causes.
#DIV/0! is the simplest. [PURE]AVERAGE[A|IF|IFS] is the most common function throwing this error, and there’s no alternative to counting the source range to trap the error, so there’s no efficient alternative check. The other common cause is the division operator, and that’s easy: X/Y becomes IF(Y<>0,X/Y,”whatever”).
#VALUE! is the most overused error value. It can result from trying to perform arithmetic with nonnumeric strings, and those errors should always propagate since they’re as likely to indicate design error as data/user error. Unfortunately, FIND and SEARCH also return #VALUE! if their 1st argument doesn’t occur in their 2nd argument. There’s no efficient alternative check. Also, matrix functions return #VALUE! when passed noncomforming/nonsquare arrays; checking array rows and columns would be efficient checks for these to avoid #VALUE! errors.
#NUM! results from invalid arithmetic exponentiation and from some numerical functions when passed invalid arguments, such as =-1^0.35, SQRT(-2) and IRR with no sign change in the cashflow. There are efficient checks for most causes.
#N/A results from lookup values not found in lookup ranges/arrays. There’s usually no efficient alternative check for exact match lookups, but standard >= lookups like =MATCH(A,B) become IF(A>=INDEX(B,1,1),MATCH(A,B),”whatever”).
So that means there are efficient ways to check arithmetic operands before performing arithmetic. There are efficient ways to check arrays before performing matrix arithmetic or calling matrix functions. There are efficient ways to catch the causes of #NUM! errors. And there are ways to catch #N/A errors from >= lookups. Unfortunately, there are no efficient ways to catch the other #DIV/0!, #VALUE! and #N/A errors.
The efficient ways to trap the other errors involve using 2 cells for 1 result. So in X99 =FIND(S,T,P) and in Y99 =IF(COUNTIF(X99,”#VALUE!”),”not found”,X99). There’s also IFERROR(ERROR.TYPE(X),0), a noncontroversial use of IFERROR, with which you could catch particular errors: IFERROR(ERROR.TYPE(X99),0)=ERROR.TYPE(#VALUE!).
And there’s always Laurent Longre’s MOREFUNC.XLL, which eliminates the need for 2 cells per result.
=IF(ISERROR(SETV(FIND(S,T,P))),IF(ERROR.TYPE(SETV(GETV()))=ERROR.TYPE(#VALUE!),”n/f”,GETV()),GETV())
FIND(S,T,P) bad example. It’d also return #VALUE! if any of its arguments were #VALUE!. Inefficiency needed.
X99: =IF(AND(ISTEXT(S),ISTEXT(T),COUNT(P)),FIND(S,T,P))
Y99: =IF(ISLOGICAL(X99),#VALUE!,IF(COUNTIF(X99,”#VALUE!”),”not found”,X99))
Exception handling in Excel is so much fun!
Good points from everyone! It’s funny how the obvious is not always talked about. In this case, reverse compatibility. IFERROR, being a nice new excel 2007 function is not compatible with excel 2003. excel 2003 users can install some kind of upgrade pack to rectify this. If your audience is still using excel 2003 you may not want to use IFERROR.
I use IFERROR to pretty up my summary tabs. I have IFERROR return a non-numeric character (“-“). You may be thinking “Hey that is a minus sign” but Excel does not see it that way. Any formula’s that use that result as part of a calculation will get the #VALUE! error. It is purely for easthetics, so I am not worried about trapping/handling specific errors. Either it’s working or it’s broken! If it’s broken I go to my source sheet to find out why. This does not work for formulas that need to return specific values based on the type of error.
I agree with Ian here. My thought is that MS incorporated this feature “IFERROR” so people could make ugly cells look pretty for reports etc., not for actual error checking. I can see where one might think to try and use it for that purpose (hence this whole discussion), but all in all I believe it is an aesthetic function.
I can think of no better way to get incorrect results than by wrapping every formula in IFERROR.
I couldn’t agree more.
IFERROR is just the logical extension of IF(ISERROR). They’re both too broad.
I would be OK with an IFERROR that allowed you to limit it to one error. Any error that you didn’t intentionally trap would get passed out of IFERROR and you could nest IFERRORs to trap more than one. Not the cleanest, but if you’re nesting seven IFERRORs it’s time to refactor.
Hmmm. Isn’t this a bit puritanical? Handling different errors differently might be on the cards for you, me, and Charles Williams because we know that there are different types of errors. But to the average spreadsheet user who previously used the IF(ISERROR then that’s not on the cards. And so IFERROR is pure gold. Not just to them, but to people who have to use and audit their sheets.
The rest of us can still write fancy functions in need that determine what type of error. But the majority of users using IFERROR won’t have the in-depth understanding that we have above.
My thought is that MS incorporated this feature “IFERROR” so people could make ugly cells look pretty for reports etc., not for actual error checking.
You might as well argue that the IF statement was incorporated by MS because people use it like this:
IF(A2=0,””,A2)
…when they could do the whole thing with no overhead using a custom number format. Cue blank stare from majority of spreadsheeters.
Isn’t this a bit puritanical?
I don’t think designing a function around ease of use trumps designing a function around exposing errors. I haven’t seen any news stories about users being frustrated with Excel. But there’s two a year about how an undetected error messed up a valuation or some such thing. I would think the Sarbanes Oxley team at MS would have been all over this function.
But we could have it both ways. Make the error type argument optional. If it’s left off, it works as it does now. If it’s included, only that type of error is trapped. I don’t think Excel needs to force people to be responsible spreadsheeters, but it should at least give us the option.
You haven’t seen any news stories about frustration with Excel, because that’s not news! Every non super-user gets frustrated. (Super-users don’t get frustrated…they get challenged. Like Kasparov does with Chess). Might as well do a news story about breathing air. Great point re having an error type optional. Mind you, I haven’t seen any news stories about people misinterpreting the optional VLOOKUP argument. ;-)
I never use IFERROR. The only real error-trapping I use in worksheets are
IF(ISNA(),,) in case a lookup value isn’t found
and
IF(denominator=0,,) to check for division by zero.
Any other error needs immediate attention.