Last month, Debra lamented:
It’s a tedious process to go through the list individually, especially since the Show Details doesn’t stay open.
I started working on a solution, but quickly grew tired of it. Then today, The Grumpy Old Programmer posted some ruby code to find the date certain blogs were last updated. It renewed my interest, so I pulled out my old code and had another look.
Right now, I’m just dumping the raw data that makes up the Show Details graph from Google Reader. It needs some more work to make it more easily readable. Here’s a sample of what the output looks like now:
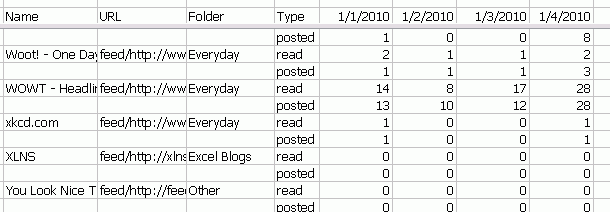
And here’s the main code
Dim xml As MSXML2.XMLHTTP60
Dim sSubUrl As String
Dim clsFeed As CFeed
Dim i As Long, j As Long
Dim xmlDom As MSXML2.DOMDocument60
Dim xmlListNode As MSXML2.IXMLDOMNode
Dim xmlFeedNode As MSXML2.IXMLDOMNode
Set gclsFeeds = New CFeeds
‘Load an XML document with your google reader subscription list
sSubUrl = “http://www.google.com/reader/api/0/subscription/list”
Set xml = New MSXML2.XMLHTTP60
xml.Open “GET”, sSubUrl
xml.setRequestHeader “Content-Type”, “text/xml”
xml.send
Set xmlDom = New MSXML2.DOMDocument60
xmlDom.loadXML xml.responseText
‘It’s got a lot of stuff, but the ‘list’ node is the money node
Set xmlListNode = xmlDom.selectSingleNode(“//list”)
‘Create a new CFeed, fill it, add it to gclsFeeds
For i = 0 To xmlListNode.childNodes.Length – 1
Set clsFeed = New CFeed
With clsFeed
.Url = xmlListNode.childNodes.Item(i).FirstChild.nodeTypedValue
.Name = xmlListNode.childNodes.Item(i).FirstChild.nextSibling.nodeTypedValue
.Folder = xmlListNode.childNodes.Item(i).FirstChild.nextSibling.nextSibling.nodeTypedValue
End With
gclsFeeds.Add clsFeed
Next i
‘Since each feeds xml with data points is different, loop through the feeds, reconstruct
‘the xml url and fill the datapoints instances
For i = 1 To gclsFeeds.Count
Set clsFeed = gclsFeeds.Item(i)
xml.Open “GET”, “http://www.google.com/reader/api/0/stream/details?s=” & clsFeed.Url
xml.setRequestHeader “Content-Type”, “text/xml”
xml.send
xmlDom.loadXML xml.responseText
Set xmlListNode = xmlDom.getElementsByTagName(“list”).Item(1)
‘This method is little atypical. I pass it a string and parse the string into
‘a proper object in the class. It’s a bit of a departure than the create-fill-add
‘paradigm used above.
For j = 0 To xmlListNode.childNodes.Length – 1
clsFeed.AddDataPoint xmlListNode.childNodes.Item(j).LastChild.nodeTypedValue
Next j
Next i
Sheet1.UsedRange.ClearContents
Sheet1.Cells(1, 1).Resize(gclsFeeds.Count * 2, 64).Value = gclsFeeds.ToRange
End Sub
You definitely want to use this code at your own risk. Also, it takes a really long time to run. Apparently the Google API uses the cookies on your computer for validation. For this code to work, I have to open Internet Explorer and login to Google Reader. Here’s an overview of what the code does:
I have a couple of custom classes, the most important of which is CFeed. Each CFeed instance holds all the data for one feed. Here’s the declaration section
Private msUrl As String
Private msFolder As String
Private mcolDataPoints As Collection
The DataPoints collection holds CDataPoint objects that look like this
Private mlDataValue As Long
Private msDataType As String
The DataType property is either “read” or “posted”.
Arnie Almighty showed me the URLs I needed to get at the xml that holds all the data. You know what’s more fun that parsing XML? Everything. Anyway, I fill all my classes by looping through the XML file and getting the data I need, including the all important URL. Then I loop through all my CFeed objects and use the URL property to get yet more XML that contains the data points. Finally, with all my classes filled, I create an array to write to the sheet. Here’s the ToRange property of the CFeeds class that produces the array:
Dim aReturn() As Variant
Dim i As Long, j As Long
Dim clsFeed As CFeed
Dim lDataCount As Long
ReDim aReturn((Me.Count * 2) + 1, Me.Item(1).DataPointCount + 4)
aReturn(1, 1) = “Name”
aReturn(1, 2) = “URL”
aReturn(1, 3) = “Folder”
aReturn(1, 4) = “Type”
For i = 2 To Me.Count * 2 Step 2
Set clsFeed = Me.Item(i / 2)
With clsFeed
aReturn(i, 1) = .Name
aReturn(i, 2) = .Url
aReturn(i, 3) = .Folder
aReturn(i, 4) = “read”
aReturn(i + 1, 4) = “posted”
clsFeed.SortDataPoints
lDataCount = 1
For j = 1 To clsFeed.DataPointCount Step 2
aReturn(1, 4 + lDataCount) = clsFeed.DataPoint(j).DataDate
aReturn(i, 4 + lDataCount) = clsFeed.DataPoint(j).DataValue
aReturn(i + 1, 4 + lDataCount) = clsFeed.DataPoint(j + 1).DataValue
lDataCount = lDataCount + 1
Next j
End With
Next i
ToRange = aReturn
End Property
For some reason the December dates are coming out as 2010 and so the sort is off. Also, I’m assuming that the XML is consistently showing “read” before “posted” so I’m not checking or sorting on that value. It’s true for every one I’ve checked, but if this code were to ever become useful, I’d want to lock that down. Actually, looking at the data in the above image for WOWT, it’s pretty clear that ‘read’ and ‘posted’ are not consistent.
You can download GoogleAPI.zip and have a look at the code if you like.
I just did this not too long ago. I used a low-tech method.
In Google Reader, I choose the Show All option (rather than Show Updated). I saw lots of feed titles that I haven’t seen in a long time. Those represent dead blogs, or blogs that have a new RSS feed URL. I updated the feed URLs for a few of them, but deleted most of them.
Thanks Dick, and lamenting sounds much more professional than whining. I downloaded your sample file, but it doesn’t set xmlListNode, so it stalls on the next line.
I barely know how to spell XML, so have no idea how to fix it.
Maybe I’ll just go low tech, like John. Sounds more relaxing.
+1 on how much fun XML can be! It’s not a format meant to be seen by humans and, worse, it’s profoundly over-used. I presume it’s the “if the only tool you have is a hammer, everything looks like a nail” principle. Except everyone has more tools than that most of the time, if they weren’t too lazy or ill-informed to look. It’s one of the reasons I liked that “HappyMapper” library so much: it let me state declaratively what I wanted from the XML and then got on and did it for me. I wonder if something like that could work for VBA – perhaps code generation could do it. Tempting – one more half-finished project couldn’t hurt, surely?
Debra: It’s probably because you don’t have Internet Explorer logged into to Google Reader. If it doesn’t see that cookie, it will return a 404, which doesn’t have a list node.
Sorry for off-topic but please Dick, how can you you browse all posts in Categories archive on your web-page? You select a category from list box, it displays first posts and then if you hit previous entries, you are somewhere else, but not in older posts of the same category.
aivars
Good question aivars – you can’t, but I’m working on it. Until I can figure out how to fix it, the best way to browse the archives is by clicking on the DDoE Archives link in the sidebar and browsing the post titles. It doesn’t limit by category, but the post titles should fairly descriptive so that you can see what looks interesting. Sorry for the broken navigation and thanks for reading.
Dick, I had Google Reader open in Firefox when testing the first time. I tried the code with Google Reader open in IE8 but got the same error there. When I put the URL in the address bar in either browser, the XML shows up.
>>XML can be! It’s not a format meant to be seen by humans and, worse, it’s profoundly over-used
I thought that was exactly what it was meant for – well at least be self descriptive!
sorry missed ;-)), off last post!
Ross
I thought the idea of XML was to be a universal transport protocol. You could receive an XML file, and with the right XLST you could render it in a browser, Excel, Word or whatever application that you want. That was how I thought it would go when I first came across it. That would have been good, the reality just seems pointless to me (and guess who has jumped in with their size 9s on this bandwagon).
Bob –
It’s not the programmers junping in with their size 9’s, it’s the clowns jumping in with their size 29’s.