In a previous post, I demonstrated how to use constants to improve your code. Then everyone started beating up my loop. The code wasn’t solving a real life problem, so I just threw any old loop together. It wasn’t relevant because that’s not what the post was about. To fight back, I created a highly improbably backstory in the comments to make my loop look at least as efficient as everyone else’s.
But no matter how crazy my story was, I couldn’t subvert Peltier’s comment about reading the range into an array. So I tried to see what kind of time differences we’re talking about. I wrote this code:
Dim lStart As Long
Dim i As Long
lStart = Timer
For i = 1 To 10
FindTotals2
Next i
Debug.Print Timer – lStart
lStart = Timer
For i = 1 To 10
UseArray
Next i
Debug.Print Timer – lStart
End Sub
Sub FindTotals2()
Dim rCell As Range
Const sFIND As String = “Total”
For Each rCell In Sheet1.Columns(1).Cells
If Left$(rCell, Len(sFIND)) = sFIND Then
‘Do something
End If
Next rCell
End Sub
Sub UseArray()
Dim vArr As Variant
Dim i As Long
Const sFIND As String = “Total”
vArr = Sheet1.Columns(1).Value
For i = LBound(vArr) To UBound(vArr)
If Left$(vArr(i, 1), Len(sFIND)) = sFIND Then
‘Do something
End If
Next i
End Sub
And got these results:
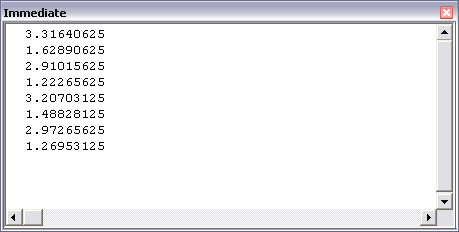
The array is quite a bit faster. I don’t think Timer is hyper-accurate, but relatively the differences are pretty clear.
Funny how your intent (to state the importance of using constants) was lost (well, ok, it was misplaced). I am often faced with two polar opposite views… (1) I want to write elegant code. This comes from years (no, decades) past where, as programmers, we were FORCED to write the most efficient code, because the hardware was limited and the alternative was horrible (yes, you too can learn to write in Assembler). (2) I want to be a prolific code writer. This comes from years of “just get it done” mentality, knowing that the hour I spend tweaking code that already works could be better spent on something new (read another paying customer). Ah, well… life is choice.
If your “Do Something” involves changing the value of each cell in column 2, you’d see much greater differences, because writing from VBA to the worksheet is much slower than reading from the worksheet into VBA.
I did my test in Excel 2003, with 65000 rows filled with the formula =”Total”&ROW(). Reading values gave me results much like Dick’s:
3.4375
1.953125
3.546875
1.0625
3.15625
1.71875
3.578125
1.15625
About 3.4 seconds for the loop and 1.5 seconds for the array.
I added a write operation to the subs:
Dim rCell As Range
Const sFIND As String = “Total”
For Each rCell In Sheet1.Columns(1).Cells
If Left$(rCell, Len(sFIND)) = sFIND Then
rCell.Offset(, 1).Value = “okay”
End If
Next rCell
End Sub
Sub UseArrayJP()
Dim vArr As Variant
Dim vOutput As Variant
Dim i As Long
Const sFIND As String = “Total”
vArr = Sheet1.Columns(1).Value
ReDim vOutput(LBound(vArr, 1) To UBound(vArr, 1), 1 To 1)
For i = LBound(vArr) To UBound(vArr)
If Left$(vArr(i, 1), Len(sFIND)) = sFIND Then
vOutput(i, 1) = “okay”
End If
Next i
Sheet1.Columns(3).Value = vOutput
End Sub
Now the results are astounding:
117.3125
4.53125
119.890625
3.875
133.65625
3.75
127.25
3.96875
Two minutes or more for the loop, and around 4 seconds for the array.
Dan –
As far as I’m concerned, elegant code is that which can be adjusted and reused with the least implementation time. The constant makes it easy to reuse the code for another situation, say I’m looking for “Sum” instead of “Total”, or I’m looking for the German replacement for “Total”.
But elegant code has to run reasonably quickly, or the user will hate it. For many years I was my own user, and in fact I started programming in Excel because I hated doing stupid stuff manually again and again. Let the computer do the work for me, right? And each time something took an annoying length of time, I’d try to improve it. I didn’t worry about cutting the machine time of a particular algorithm from 100 to 50 ms, but I did care about speeding up a 30-second data dump into the worksheet. I still program with this in mind. The user is going to take seconds or minutes to decide what to do next, so saving a second on a short operation doesn’t matter much. But once the user clicks a button, I want them to get their output quickly.
Jon included the write time in his calculations.
You can’t make time comparisons accurately without doing that.
Very large arrays can consume prodigious amounts of memory and require as much or MORE time to plug in a worksheet as just directly writing to each cell.
I found in adding large random value array sets (500,000 elements) to a worksheet (3300 rows by 150 columns) that using a smaller array set (3300 x 1), filling it inside a loop and placing it on a worksheet 150 times was much much faster.
Apologies for the beating. But label anything “best practice” in an expert forum with some old x just thrown into it…
My point was only that if using whole columns was a minor annoyance before, it has grown into a real real life problem with the new row count. You used to appreciate this kind of feedback.
Oh I still do appreciate it. As you can tell from my comment I’m still in the 2003 grid size, so it’s a point well taken that that kind of sloppy code is now more than just sloppy code.
Incidentally, when “looping” my first instinct is to use the Find method. But surprisingly about half of the time I find I need another Find, so I’m stuck looping inside the Find’s loop. Still, it’s better than two loops. After Find, I fall back to Intersect(Column, UsedRange), but I really should be using SpecialCells when it’s appropriate. That’s one that I need to force myself to do so that it becomes habit.
Jim – Good point. Of course, if you’re writing a formula, you can write a large range in one go, which was my point about using an array.
Dick – I didn’t really come across SpecialCells until fairly recently, a couple years ago, and I’m always happy to use it. Of course, there’s the error if your special cells range has more than 8192 areas, which our friend Ron de Bruin has documented for us. In fact, he told me about it, and a week later I came across the error. Since it was fresh, I solved the problem in about five minutes, and my client thought I was brilliant. Thanks, Ron!
You should move the Len(sFind) outside the loop. Recalculating the length of a constant in each pass adds unnecessary overhead.
Better make lStart a double, rather than long.
I got these results with 2007:
XL2007 Range/Array
2.55078125
0.800781253.19
2.55078125
0.800781253.19
2.546875
0.82031253.10
2.58984375
0.8125 3.19
2.58984375
0.8125 3.19
And these with 2000:
XL2000Range/Array
2.04296875
0.67968753.01
2.0546875
0.691406252.97
2.0546875
0.691406252.97
2.06640625
0.69531252.97
2.07421875
0.69531252.98
To do this test I filled column A with text, to see if that made any difference. It didn’t, but in XL2007 when I try to erase the text or delete the rows it locks up, and I have to close Excel down with Task Manager.
Does anyone else get that?
Bit off topic but, I was working with some large size arrays recently and kept getting a memory error. This only happened when I returned strings, to a variant, it was ok with ints.
I think (can’t quite remember now!) i re-typed the array to a string and it worked ok with strings. But it was not something I was expecting.
(yes, I had a reason for using a variant in the first place(I hope!))
Just a small quibble, but when I ran the code, I got the second one taking negative time! All because your lStart is defined as a Long, so the Timer gets rounded to the nearest integer. It should be a Double.
For some reason I thought Timer was a Long. I guess all those decimal places should have tipped me off. Help says it’s a Single, so you guys are right. Also, moving the Len outside the loop is good tip, so thanks Nicholas.
Using .Find is very sensitive to the number of hits: so with Dick’s (extreme) test case .find is by far the slowest, but if you invert the test (so you are looking for 10 hits out of 65000) it becomes the fastest.
Some minor quibbles with other solutions:
– I almost never use .Text because it can return #### if the column size is too small or the user may have changed the formatting(and .Text can do funny things in UDFs)
– If Left$(vArr(i, 1), Len(sFIND)) = sFIND Then does not work if any of the text is shorter than sFind
– Using Instr does not necessarily give the same solution as Left or Like Total* because it will also find SubTotal for example
Charles –
As fzz wrote
“If InStr(1, c.Text, s2m) = 1 Then”
Only checks passes for “Total” at the left. I too tend to use
If InStr() Then
but fzz was more specific.
…mrt
Michael,
You are absolutely correct,
apologies to fzz …
Six comments. But first, don’t get me wrong. I often use the variant=range.value (and reverse) in my code. It almost always improves performance. However, as I mentioned in the other discussion, most of the time the primary motivation is flexibility.
(1) Since Dick did not output the result of his “do something,” he missed something that Jon ought to have caught with his version of the code. The code using the variant=range.value and range.value=variant is *not* functionally identical to the one that loops through the cells one at a time! The variant version replaces all the cells in the output column whereas the cell-at-a-time code only updates those cells where the If test yields True!
(2) The var=range.value method works only if we want to work with data and not with the Excel object. So, if Dick wanted to change the font color or the background color or, as Andy did, bold the cells, this method would not work.
(3) Optimizations are not always data-independent. I created 2 data sets. The first consisted of 65536 cells in column A with the formula =IF(MOD(ROW(),100)=0,”abc”&ROW(),”Total”&ROW()). This yields a lot of cells starting with “Total”. I also created the “inverse” set with the formula =IF(MOD(ROW(),100)<>0,”abc”&ROW(),”Total”&ROW()) This of course, had only 1 out of every 100 rows starting with “Total”
I also reported the results not just in total time but also on a “per-cell” basis. My results were
0.203125 3.09944152832031E-06
0.78125 1.19209289550781E-05
0.125 1.9073486328125E-06
So, while the variant=range.value code is always faster than the cell-at-a-time code, the benefit varies based on the data set.
(4) All the different samples relied on testing just the interface without accounting for what the core “do something” code does. Let’s use the above numbers to establish a baseline. If the core “do something” code runs much faster than 1.2E-5 to 7.2E-4 seconds, the interface does matter! However, the longer that the core code takes, the less the interface matters.
Some time ago, I was asked by a client to improve the performance of some code. It used several PivotTables to analyze the raw data and then extracted and organized the data from the resulting PivotTables into tables and charts that the client wanted. The client told me their IT group was overloaded and couldn’t work on the problem but the IT person was certain the problem was with the tables and charts that were being created.
The first thing I did was add a bunch of timing code to find where the problem was. It turned out the original code created a PT, used the data from the first row, and then ‘hid’ that PT element. The last part, i.e., hiding the element, could, under certain circumstances, take a long time. So, I rewrote the code to simply step through each row of the PT and performance improved by a magnitude!
Contrary to the IT expert, the performance problem had nothing to do with the number of charts or updating the charts or whatever.
My point about the story is preemptive (and premature) decisions about optimization may often be nothing but a waste of time.
(5) Using other algorithms: Data independent performance. Can we make our code performance independent of data? Given that we are dealing with Excel, yes, within limits. If we want to add something in an adjacent column (as Jon did in his example), we can use
With Rng.Offset(0, 1)
.FormulaR1C1 = _
“=IF(LEFT(RC[-1],LEN(““Total”“))=”“Total”“,”“okay”“,”“”“)”
.Value = .Value
End With
End Sub
We could also add conditional formatting, etc., though we would have a hard time working with the entire row.
How well does the above code perform? With only a few cells starting with “Total”, it took 0.25 seconds and with lots of cells starting with “Total”, it took 0.27 seconds. Clearly, it is almost totally data-independent. Not to mention it is easy to write, understand, and maintain! And, as a bonus, it is very fast!
(6) Using other algorithms: Convenience. How about an algorithm that provides programming convenience? I used the FindAll method I wrote some time ago (http://www.tushar-mehta.com/excel/tips/findall.html)
FindAll(“Total*”, Rng, LookIn:=xlValues, LookAt:=xlWhole).Offset(0, 4).Value = “okay”
End Sub
Note that this is the first algorithm that does exactly what the original code did. It only updates those cells where the adjacent cell starts with “Total.” So, in that sense this is the only truly comparable method! It also retains the ability to work with the Excel object.
How well does it perform. Well, with a lot of cells starting with “Total” it took about 56 seconds and with a few cells it took about 0.6 seconds. So, it is faster than the cell-by-cell method by just under 25%.
Summary: Optimization is rarely as easy as people make it out to be. Most people focus on micro-optimizations that are rarely truly beneficial. Optimizations can also be such that they don’t truly duplicate the functionality of the original code. Finally, optimizing without understanding the true nature of the bottleneck doesn’t always yield the expected benefits, not to mention that it may take away some of the flexibility embedded in the original code.
Wow, I just realized why I started reading this blog… for the high value posting! Dick it looks like you beat me to it with your own test that shows the loop speed. Thanks as well to Jon, Charles and Tushar for the excellent info, I might actually have to print this thread out and spend some time digesting.
Thx,
JP
Tushar –
Nice analysis.
(1) I did in fact notice this, and thought about loading column 2 into a second array, so that any blanks in my output array did not overwrite any values in that column, but it was getting late….
(2) Not true. I can test the element of the array, then bold the corresponding cell in the sheet. This still minimizes interaction with the worksheet (though of course reading a value is much faster than changing a format).
(3) I assumed this, and was going to run a nice model to demonstrate, but the data didn’t show the nice behavior I’d expected.
(4) Interface matters. I don’t kill myself optimizing a two second routine if the user spends five minutes thinking about what the analysis means.
(5) I like this approach, depending on what the “do something” means. If you put a formula in place that is based on column 1, it updates from that point on without rerunning the code.
(7) “Optimization is rarely as easy as people make it out to be.” Yes sir. To me, optimization is about making something modular so I can reuse it with little fuss, and making it self-documenting so I can remember how it works quickly. The whole array thing works for me as for you, because I have a set of library routines that process arrays, and supporting routines that do range-array and csv-array and similar translations. Optimization for my projects is more about streamlining development processes rather than code execution processes.