How’s that title for Google-ability. Pretty saucy, I’d say. Here’s an affiliate link if you’re in the market for one of these label printers.


LabelWriter 450
Back in 2010, I was printing labels on a Dymo from VBA. At my current job, I had occasion to do it again, so I bought a LabelWriter 450 from Amazon. Seventy-five bucks! What a deal.
Previously I didn’t need anything fancy formatting-wise. I could just push some text at a DymoLabels object and print it. I’m not so lucky this time around. I really needed some underlines for visual separation of data. I don’t see any way to underline stuff through the Dymo object model. But what I did discover was that the .label files created by their software are just XML files. Woot!
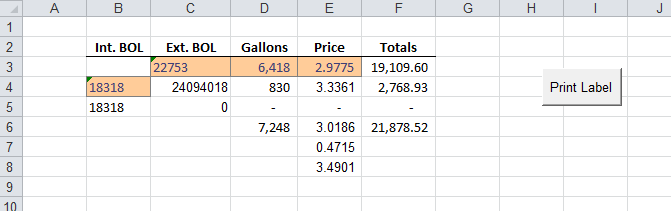
Rather than trying to navigate a klunky object model, I can just write to a text file. Here’s what the new labels look like.

And here’s a piece of the XML file.
Int BOL Ext BOL Gallons Price Total
22753 6,418 2.9775 19,109.60
18318 24094018 830 3.3361 2,768.93
18318 0
The XML isn’t terribly pretty mostly because there are line feeds in there. Without the line feeds, I think it would be indented properly. Each Element tag has a String tag and an Attributes tag. It looks like every font attribute is listed whether you specifically set it or not. I’m also padding my text with spaces to line up columns. I could use multiple text boxes, but there is no grid control. For now, this works. The only downside to using one big textbox and space padding is that I have to use a fixed-width font – Courier New in this case. If I want to use a nicer font, I’ll have to go the multiple textbox route.
I have this form for data input and a button to print the label. The button kicks off the code below. I don’t need the mdyLabel variable any more because I’m not using that part of the object model. Instead of mdyLabel, I’m manipulating the XML file directly giving me more control.
Sub PrintBlendCalc()
Dim vaPrinters As Variant
Dim i As Long
Dim sFile As String
Const sMSGNODYMO As String = "Dymo label printer not found."
If mdyAddin Is Nothing Then
CreateDymoObjects
End If
If Not mdyAddin Is Nothing Then
vaPrinters = Split(mdyAddin.GetDymoPrinters, "|")
For i = LBound(vaPrinters) To UBound(vaPrinters)
If mdyAddin.IsPrinterOnline(vaPrinters(i)) Then
mdyAddin.SelectPrinter vaPrinters(i)
Exit For
End If
Next i
UpdateLabelFile sFile
mdyAddin.Open sFile
mdyAddin.Print2 1, True, 1
Else
MsgBox sMSGNODYMO, vbOKOnly
End If
End Sub
Instead of using the SetField method (like in the previous example), I call a new procedure called UpdateLabel file to create a new XML file. Then I open the file and print it.
Public Sub UpdateLabelFile(ByRef sFile As String)
Dim xDoc As MSXML2.DOMDocument
Dim xStrings As MSXML2.IXMLDOMSelection
Dim vaData As Variant
'Get the label data in an array
vaData = wshBlendCalc.Range("B2").Resize(7, 5).Value
'Create a new XML Doc and load the template label
Set xDoc = New MSXML2.DOMDocument
xDoc.Load msLABELPATH & "BlendCalc.label"
'Get all the "String" elements (there are 4)
Set xStrings = xDoc.getElementsByTagName("String")
'Change the text of the four string elements
xStrings(0).Text = FormatLabelText(vaData, 1)
xStrings(1).Text = FormatLabelText(vaData, 2) & FormatLabelText(vaData, 3)
xStrings(2).Text = FormatLabelText(vaData, 4)
xStrings(3).Text = FormatLabelText(vaData, 5) & FormatLabelText(vaData, 6) & FormatLabelText(vaData, 7)
'Save the XML file
sFile = msLABELPATH & "NewOrders\" & vaData(2, 2) & "_blend.label"
xDoc.Save sFile
'Save the data to a text file for those people who don't read XML that well
Open msLABELPATH & "NewOrders\" & vaData(2, 2) & "_blend.txt" For Output As #1
Print #1, FormatLabelText(vaData, 1) & _
FormatLabelText(vaData, 2) & _
FormatLabelText(vaData, 3) & _
FormatLabelText(vaData, 4) & _
FormatLabelText(vaData, 5) & _
FormatLabelText(vaData, 6) & _
FormatLabelText(vaData, 7)
Close #1
End Sub
There are four elements in my XML file. The first label line is underlined, so that gets its own element. The second and third lines and a portion of the fourth line have the same attributes, so they’re grouped into one element. The portion of the fourth line that is underlined is in the third element. And all the rest of the text goes into the fourth element. The elements are set and the attributes are just the way I want them, so all that is left is to update the text.
I pass the array into a FormatLabelText function which extracts the data I want and pads the spaces so the columns line up. The FormatLabelText function is shown below.
I pass the sFile variable ByRef into UpdateLabelFile. The sFile variable is set and retains that value back in the calling procedure so the calling procedure knows which file to open and print.
The FormatLabelText function takes the array and whichever row we’re interested in formatting. It starts by defining three arrays: vaBuffer defines how much padding for each of the five columns; vaAlignLeft defines if the columns are aligned right or left; and vaFormat defines the number format for each of the five column (@ is the format for general text).
Public Function FormatLabelText(ByRef vaData As Variant, ByVal lIndex As Long) As String
Dim sReturn As String
Dim vaBuffer As Variant
Dim vaAlignLeft As Variant
Dim vaFormat As Variant
Dim sData As String
Dim j As Long
vaBuffer = Array(9, 11, 11, 8, 10)
vaAlignLeft = Array(True, True, False, False, False)
vaFormat = Array("@", "@", "#,##0", "0.0000", "###,##0.00")
For j = LBound(vaData, 2) To UBound(vaData, 2)
sData = Format(vaData(lIndex, j), vaFormat(j - 1))
If Len(sData) = 0 Then
sData = Space(vaBuffer(j - 1))
ElseIf Len(sData) > vaBuffer(j - 1) Then
sData = Left$(sData, vaBuffer(j - 1) - 1) & Chr$(133)
ElseIf Len(sData) < vaBuffer(j - 1) Then
If vaAlignLeft(j - 1) Then
sData = sData & Space(vaBuffer(j - 1) - Len(sData))
Else
sData = Space(vaBuffer(j - 1) - Len(sData)) & sData
End If
End If
sReturn = sReturn & sData
Next j
FormatLabelText = sReturn & vbNewLine
End Function
First the data is formatted using the Format function and the vaFormat array. Next, the big If..ElseIf..EndIf block determines how to pad the data with spaces.
- If the data is empty (Len = 0) then write spaces for the whole buffer.
- If the data length is greater than the buffer, truncate it and add an ellipse to the end.
- If the data length is less than the buffer, add spaces to the end (or the beginning if it's aligned right) to fill it out.
It would be nice (but hard) to create a more general purpose function that created a label from a range. But this works for now.